This section applies only if the clustering mode is set to
AUTOMATIC
or
BY_CLUSTER_IDS
. Both modes work in a similar way. The main difference is that
the clustering mode
AUTOMATIC
can handle graphs where clusters are not or only partially
specified; the clustering mode
BY_CLUSTER_IDS
requires a full specification of all clusters and throws an
exception when performing a layout on a graph with incomplete
cluster specification.
Cluster membership and order of the nodes in a cluster (CL)
Specifying clusters explicitly is not necessary in clustering
mode
BY_SUBGRAPHS
, because the subgraphs form the clusters. In clustering mode
AUTOMATIC
, clusters can optionally be specified. In mode
BY_CLUSTER_IDS
, they must be specified before performing the layout.
Example of specifying node cluster (CL
algorithm)
To specify to which cluster each node of
the graph belongs:
In CSS
You must declare the clustering
information in the node rules, like this:
node {
...
ClusterId : "@clusterIds";
StarCenter : "@starCenter";
}
where
clusterIds
refers to a node property whose value in the data model is
given in the following syntax:
<cluster-id>,<index>;<cluster-id>,<index>;...
. Each
cluster-id
,
index
pair represents the identifier of the cluster and the ordering
index of the node in this cluster. The index can be omitted.
If only one pair is specified, this means the node belongs to
only one cluster. If several pairs are specified for a node,
this means that this node belongs to more than one cluster.
In the node rule above,
starCenter
is a node property whose value in the data model must be
either “true” of “false”. The nodes for which the value is
“true” are considered “star centers” by the layout algorithm
(see Star clusters (CL)).
In Java
To specify the cluster membership, use a cluster identifier;
that is, an instance of a subclass of the class IlvClusterId (which is abstract). Two
subclasses are provided:
- IlvClusterNumber, which uses integer numbers as cluster identifiers.
- IlvClusterName, which uses string names as cluster identifiers.
You can combine these two types of identifiers as any other
subclass of
IlvClusterId
. For example, you can write:
// create identifier for first cluster (integer)
IlvClusterNumber clusterId1 = new IlvClusterNumber(1);
// create identifier for second cluster (string)
IlvClusterNumber clusterId2 = new IlvClusterName("R&D network");
Then, if
node1
to
node3
belong to the first cluster, you can write:
layout.setClusterId(node1, clusterId1); layout.setClusterId(node2, clusterId1); layout.setClusterId(node3, clusterId1);
Assume that
layout
is an instance of
IlvCircularLayout
.
If you want the nodes to be drawn in a special order (for
example,
node1
->
node2
->
node3
), you must also specify an index (an integer value) for each
node:
layout.setClusterId(node1, clusterId1, 0); layout.setClusterId(node2, clusterId1, 1); layout.setClusterId(node3, clusterId1, 2);
Two methods allow you to specify the
cluster to which a node belongs:
void setClusterId(Object node, IlvClusterId clusterId)
void addClusterId(Object node, IlvClusterId clusterId)
If you call the first method, the node belongs only to the
cluster whose identifier is
clusterId
. The second method allows you to specify that a node belongs
to more than one cluster.
These methods have another version with
an additional argument, an integer value representing the
index:
void setClusterId(Object node, IlvClusterId clusterId, int index)
void addClusterId(Object node, IlvClusterId clusterId, int index)
This value is used to order the nodes
on the cluster. If you specify these indices, the algorithm
sorts the nodes in ascending order according to the index
values.
The values of the index cannot be
negative. They do not need to be continuous; only the order of
the values is important.
To obtain the specified index of a node
in a given cluster, use the method:
int getIndex(Object node, IlvClusterId clusterId)
If no index is specified for the node, the method returns the
value
IlvCircularLayout.NO_INDEX
. It is a negative value.
To obtain an enumeration of the cluster
identifiers for the clusters to which the node belongs, use
the method:
Enumeration getClusterIds(Object node)
The elements of the enumeration are instances of a subclass of
IlvClusterId
.
To efficiently obtain the number of
clusters to which a node belongs, use the method:
int getClusterIdsCount(Object node)
To remove a node from the cluster with
the specified identifier, use the method:
void removeClusterId(Object node, IlvClusterId clusterId)
To remove a node from all the clusters
to which it belongs, use the method:
void removeAllClusterIds(Object node)
Root clusters (CL)
The algorithm arranges the clusters of each connected component of the graph of
clusters around a “root cluster”. By default, the algorithm can
choose this cluster. Optionally, you can specify one or more root
clusters (one for each connected component).
Example of specifying root clusters (CL
algorithm)
To specify one or more root clusters
(one for each connected component):
In CSS
It is not possible to specify root
clusters in CSS.
In Java
Use the method:
void setRootClusterId(IlvClusterId clusterId)
To obtain an enumeration of the
identifiers of the clusters that have been specified as root
clusters, use the method:
Enumeration getRootClusterIds()
This parameter has no effect if the clustering mode is
BY_SUBGRAPHS
.
Star clusters (CL)
Example of specifying star center (CL
algorithm)
To specify whether a node is the center
of a star:
In CSS
Add to the
GraphLayout
section:
starCenter : "true";
In Java
Use the method:
void setStarCenter(Object node, boolean starCenter)
To know whether a node is the center of
a star, use the method:
boolean isStarCenter(Object node)
By default, a node is not the center of a
star.
This parameter has no effect if the clustering mode is
BY_SUBGRAPHS
.
Get the contents, the position, and the size of the clusters (CL)
At times, you might need to know the position and the size of
the circle on which the nodes for each cluster are drawn. It
may be the case if you want to perform some reshaping
operations on the links. To do so, you can obtain a vector
containing all the cluster identifiers after the layout is
performed. In clustering mode
AUTOMATIC
, the vector can contain generated cluster identifiers if no
clusters were specified.
Example of obtaining a vector that
contains all the cluster identifiers (CL algorithm)
To obtain a vector containing all the
cluster identifiers after the layout is performed:
In CSS
It is not possible to get the
contents, position, or size of the clusters via CSS.
To obtain a vector containing all the
cluster identifiers after the layout is performed:
In Java
Use the method:
Vector getClusterIds()
The vector contains instances of a subclass of
IlvClusterId
. By browsing the elements of this
Vector
, you can get the necessary information for each cluster:
float getClusterRadius(int clusterIndex)
IlvPoint getClusterCenter(int clusterIndex)
Vector getClusterNodes(int clusterIndex)
The
getClusterNodes
method returns the nodes that make up the cluster. The
argument
clusterIndex
represents the position of the cluster in the
Vector
returned by the method
getClusterIds()
.
Do not use these methods if the clustering mode is
BY_SUBGRAPHS
.
Dimensional parameters (CL)
This section illustrates the dimensional
parameters used in the Circular Layout algorithm. These
parameters are explained in the sections that follow.
The clustering mode
BY_CLUSTER_IDS
also works with a disconnected graph offset. It is explained in
the section Handling of disconnected graphs.
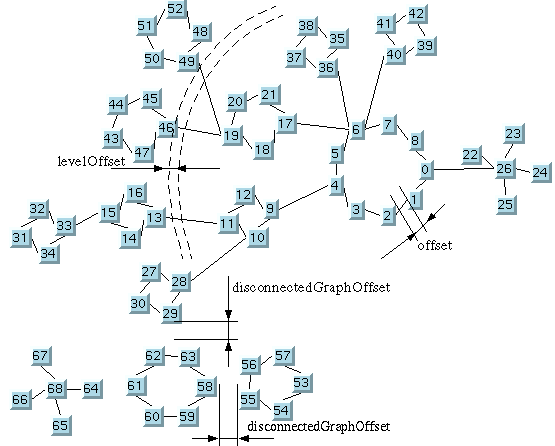
Dimensional parameters for the
Circular Layout algorithm
Offset (CL)
The layout algorithm tries to preserve a minimum distance
between nodes (see figure Dimensional parameters for the Circular
Layout algorithm).
Example of specifying the offset (CL
algorithm)
To specify the offset:
In CSS
Add to the
GraphLayout
section:
offset: "20.0";
In Java
Use the method:
void setOffset(float offset)
Level offset (CL)
If the clustering mode is
BY_SUBGRAPHS
, the level offset parameter controls the minimal offset
between nodes that belong to the same cluster.
If the clustering mode is
BY_CLUSTER_IDS
, the following scenario applies.
As explained in The CL algorithm, interconnected rings
and clusters are drawn on concentric circles around a root
cluster. The radius of each concentric circle is computed to
avoid overlapping clusters. In some cases, you might want to
increase this radius to obtain a clearer drawing of the
network. To meet this purpose, the radius is systematically
increased with a “level offset” value (see figure Dimensional parameters for the Circular
Layout algorithm).
Example of specifying the level offset
(CL algorithm)
To specify the level offset:
In CSS
Add to the
GraphLayout
section:
levelOffset : "30.0";
In Java
Use the method:
void setLevelOffset(float offset)
The default value is zero.
This parameter has no effect if the clustering mode is
BY_SUBGRAPHS
.