Conversion
Overview
As described in Representing Text in Computers, a character encoding is a mapping from a set of abstract characters to a set of nonnegative integers. The result specifies how characters can be represented numerically within a computer. The integer associated with an abstract character in an encoding is called the code point for the character.
A conversion is the process of mapping characters from one character encoding to another. For example, the Chinese character 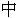 (meaning “middle, center”) is encoded in UTF-16 with code point 4E2D, but represented in the Big5 encoding by code point A4A4. Note that conversion does not change the characters themselves; it merely changes the numbers used to represent those characters within the computer.
(meaning “middle, center”) is encoded in UTF-16 with code point 4E2D, but represented in the Big5 encoding by code point A4A4. Note that conversion does not change the characters themselves; it merely changes the numbers used to represent those characters within the computer.
(meaning “middle, center”) is encoded in UTF-16 with code point 4E2D, but represented in the Big5 encoding by code point A4A4. Note that conversion does not change the characters themselves; it merely changes the numbers used to represent those characters within the computer.The Internationalization Module uses the UTF-16 character encoding form to represent Unicode strings. In UTF-16, each 21-bit Unicode code point is represented using one or two 16-bit code units. (See The Unicode Standard.) The Internationalization Module provides conversion classes that let you convert strings from every standard encoding into UTF-16, and convert UTF-16 strings into any recognized encoding.
This chapter describes how to:
Note that the Internationalization Module does not directly convert between arbitrary encodings. However, you can do so indirectly by first converting a string to UTF-16, then reconverting the string from UTF-16 to the target encoding.




