Forward Selection
Unlike exhaustive search, forward selection is always computationally tractable. Even in the worst case, it checks a much smaller number of subsets before finishing. This technique adds predictor variables and never deletes them. The starting subset in forward selection is the empty set. For a regression model with N possible predictor variables, the first step involves evaluating N predictor variable subsets, each consisting of a single predictor variable, and selecting the one with the highest evaluation criterion. The next step selects from among N – 1 subsets, the next step from N – 2 subsets, and so on. Even if all predictor variables are selected, at most N((N + 1)/2) subsets are evaluated before the search ends.
The problem with forward selection is that, unlike exhaustive search, it is not guaranteed to find the subset with the highest evaluation criterion. In practice, however, many researchers have reported good results with forward selection (A. J. Miller, Subset Selection in Regression, Chapman & Hall, 1990). This is not too surprising: it’s not hard to show that forward selection will find the subset with the highest evaluation criterion when predictor variables are statistically independent and the observation variable is modeled as a linear combination of predictor variables. Actually, it still holds for an observation variable y and predictor variables xi such that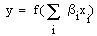
where f() is any monotonic, continuously differentiable function. While statistical independence of predictor variables may be too much to expect for the regression problem you are trying to improve, it may become more feasible with more study into the predictor variables. You may discover certain preprocessing steps that can be performed to predictor variable data such that the predictor variables become nearly statistically independent.




