Explicitly Formatted Input and Output
Explicit formatting allows a great deal of flexibility in specifying exactly how ASCII data is formatted. Formats are specified using a syntax that is very similar to that used in FORTRAN or C format statements. Scientists and engineers already familiar with FORTRAN or C will find PV-WAVE formats easy to write.
The routines for performing explicitly (fixed) formatted ASCII I/O are listed in "ASCII I/O—Fixed Format".
All data is handled in terms of basic data types. Thus, an array is considered to be a collection of scalar data elements, and a structure is processed in terms of its basic components. Complex scalar values are treated as two floating-point values.
Using FORTRAN or C Formats for Data Transfer
All formatted ASCII I/O routines recognize FORTRAN-style format strings, and for formatted I/O routines that begin with the prefix “DC”, C-style format strings can be used, as well. The format string specifies the format in which data is to be transferred as well as the data conversion required to achieve that format.
FORTRAN and C data transfer codes are discussed in more detail in Appendix A: Format Strings. You can also find examples of using format codes with any of the descriptions of the commands for transferring explicitly formatted data; these descriptions are in the PV‑WAVE Reference.
How is the Format String Interpreted?
The variable names provided in a call to an I/O routine comprise the variable list. The variable list specifies the data to be moved between memory and the file. The Format keyword can be included in the parameter list of an ASCII I/O routine to provide a format string that explicitly specifies the appearance of the transferred data.
The format string is traversed from left to right, processing each record terminator and format code until an error occurs, or until no variables are left in the variable list. In FORTRAN-style formats, the comma field separator serves no purpose except to delimit the format codes.
When reading or writing data from the file, the data is formatted according to the format string. If the data type of the input data does not agree with the data type of the variable that is to receive the result, PV-WAVE performs type conversion if possible, and otherwise, issues a type conversion error and stops.
If the last closing parenthesis of the format string is reached and there are no variables left in the variable list, then format processing terminates. If, however, there are still variables to be processed in the variable list, then part or all of the format specification is reused. This process is called format reversion, and is discussed more in "Format Reversion".
In a FORTRAN-style format string, when a slash ( / ) or newline record terminator is encountered, the current record is completed and a new one is started. For output, this means that a new line is started. For input, it means that the rest of the current input record is ignored, and the next input record is read.
When a format code that does not transfer data is encountered, it is processed according to its meaning. When a format code that transfers data is encountered, it is matched up with the next entry in the variable list. All recognized format codes are listed in Appendix A: Format Strings.
note | It is an error to specify a variable list with a format string that doesn’t contain a format code that transfers data to or from the variable list. Because the command expects to transfer data to the variables in the variable list, an infinite loop would result. For example, consider the following statement: |
PRINTF, 1, names, years, salary, Format= $
'("Name", 28X, "Year", 4X, "Total Salary")'
This statement results in a message stating that an infinite loop is detected (because no data is being transferred to the named variables), and thus execution is being halted. On the other hand, the following statement is acceptable because there are no variables included as part of the parameter list:
PRINTF, 1, Format= $
'("Name", 28X, "Year", 4X, "Total Salary")'
Should I Use a FORTRAN or C Format?
The only functions that recognize the C format strings are those that begin with the prefix “DC”. The DC functions are the ones that have been designed specifically to simplify the process of transferring data.
All other procedures and functions that transfer data recognize only the FORTRAN-style format statements. The FORTRAN format codes that are recognized by PV-WAVE are listed in Appendix A: Format Strings.
Format Reversion
Format reversion is a way to transfer a lot of data with a format string that, at first glance, seems to be “too short”. When using format reversion, the current record is terminated, a new one is started, and format control reverts to the first group repeat specification that does not have an explicit repeat factor.
note | If you are using a C-style format string, the entire format string is reused. |
If the format does not contain a group repeat specification, format control returns to the initial opening parenthesis of the format string. For example, the command:
PRINT, Format = $
'("The values are: ", 2("<", I1, ">"))', INDGEN(6)
results in the output:
The values are: <0><1>
<2><3>
<4><5>
The process involved in generating this output is:
1. Output the string, “The values are:”.
2. Process the group specification and output the first two values. The end of the format specification is encountered, so end the output record. Data remains, so revert to the group specification
2("<", I1, ">")using format reversion.
3. Repeat the second step until no data remains, and then for output, end the output record, or for input, stop reading data values.
At this point, format processing is complete. To see other examples of format reversion, refer to Appendix A: Format Strings.
Transferring Date/Time Data
PV-WAVE supports the transfer of date/time data in and out of data files. Some examples of date/time data which you may wish to read are:
10/20/92 12:00:10.90
21/01/93 11:06:29.0875
10-JAN-1992 12:46
MAR:1993 $25440.0
Although there are several ways to read data/time data, you would want to choose the method that makes the most sense for your application and best matches the style of program you are writing:
Method 2 utilizes the DC_READ routines. As discussed in "Functions for Simplified Data Connectivity", the DC routines have been provided as yet another alternative for the process of transferring data in and out of PV-WAVE.
Date/Time Templates
The templates that can be used with the formatted ASCII I/O routines are shown in Table 9-8: Templates for Transferring Date/Time Data.
Number | Template Description |
|---|---|
1 | MM*DD*YY[YY] |
2 | DD*MM*YY[YY] |
3 | ddd*YY[YY] |
4 | DD*mmm[mmmmmm]*YY[YY] |
5 | [YY]YY*MM*DD |
–1 | HH*MnMn*SS[.SSSS] |
–2 | HHMnMn |
M = Month, D = Day, Y = Year, H = Hour, Mn = Minute, S = Second The asterisk (*) shown above represents a delimiter that separates the different fields of data. The delimiter can also be a slash (/), a colon (:), a hyphen (-), or a comma (,). | |
Positive template numbers are for transferring date data, while negative template numbers are for transferring time data. To see examples of the types of data that can be transferred using each of these templates, refer to Working with Date/Time Data in the PV‑WAVE User’s Guide.
Example—Reading Date/Time Data
Assume that you have a file, chrono.dat, that contains some data values, including a three-character label showing where the data was recorded, and also some chronological information about when those data values were recorded:
LAM 10/02/90 09:32:00 10.00 32767
COS 10/02/90 09:36:00 15.89 99999
SNV 10/02/90 09:37:00 14.22 87654
Method 1—Read the File with READF
To read the label from the first column into a string variable, the date and time from the second and third columns into one date/time variable and read the fourth and fifth columns of data into another two variables, use the following commands:
loc = STRARR(3) & calib = LONARR(3)
date1 = STRARR(3) & time1 = STRARR(3)
; Create variables to hold the location, calibration, date, time,
; and decibel level.
decibels = FLTARR(3)
; Open data file for input.
OPENR, 1, 'chrono.dat'
; Define scalar strings and a long integer scalar.
locs = ' ' & date1s = locs & time1s = date1s
calibs = 1L
; Initialize counter.
I = 0
; Loop over each record of data.
WHILE (NOT EOF(1)) DO BEGIN
; Read scalars; the first three are string variables, the
; fourth is a float, and the fifth one is an integer.
READF, 1, locs, date1s, time1s, decibelss, calibs, Format = $
"(A3, 2(1X, A8), 1X, F5.2, 1X, I5)"
; Store in each vector.
loc(I) = locs & date1(I) = date1s & $
time1(I) = time1s & calib(I) = calibs $
& decibels(I) = decibelss
; Increment counter and check for too many records.
IF I LE 2 THEN I = I+1 ELSE CLOSE, 1 & $
STOP, "Too many records."
ENDWHILE
; Close the file.
CLOSE, 1
; Use one of the conversion utilities, STR_TO_DT, to convert
; the strings to date/time data. The variable date1 uses
; Template 1, while the variable time1 uses Template –1. The
; result array, my_dt_arr, holds both the MM/DD/YY and the
; HH:MM:SS data.
my_dt_arr = STR_TO_DT(date1, time1, Date_Fmt=1, Time_Fmt = –1)
Another alternative is to read the time and date data as integers instead of strings. This is the approach you must take if your time/date data does not have the customary delimiters separating the months, days, and years, or the hours, minutes, and seconds, as shown in the sample file below:
LAM 100290 093200 10.00 32767
COS 100290 093600 15.89 99999
SNV 100290 093700 14.22 87654
In this situation, instead of defining date1 and time1 to be strings, you would define different variables—one for each component of the date/time data:
; Define integer arrays to hold the months, days, years, hours,
; minutes, and seconds data.
year = INTARR(3) & mon = year & day = year
hour = INTARR(3) & min = hour & sec = hour
; Define integer scalars for use inside the read loop.
years = 0 & mons = 0 & days = 0
hours = 0 & mins = 0 & secs = 0
; Create variables to hold location, calibration, and decibel
; level.
loc = STRARR(3) & calib = LONARR(3)
decibels = FLTARR(3)
; Initialize string and long integer scalars.
locs = ' ' & calibs = 1L
; Open data file for input.
OPENR, 1, 'chrono.dat'
; Initialize counter.
I = 0
; Beginning of read loop.
WHILE NOT EOF(1) DO BEGIN
; Read scalars; first one is a string variable, the next six
; are integer variables, the eighth is a float, and the ninth
; one is an integer.
READF, 1, locs, mons, days, years, hours, mins, secs, $
decibelss, calibs, Format = $
"(A3, 2(1X, 3(I2)), 1X, F5.2, 1X, I5)"
; Store in each vector.
year(I) = years & mon(I)= mons
day(I) = days & hour(I) = hours
min(I) = mins & sec(I) = secs
; Increment counter and check for too many records.
IF I LE 2 THEN I = I+1 ELSE CLOSE, 1 & $
STOP, "Too many records."
ENDWHILE
CLOSE, 1
Now that the date/time data has been read into variables, these variables can be used as input to the conversion utility, VAR_TO_DT:
; Use one of the conversion utilities, VAR_TO_DT, to convert the
; variables to date/time format.
my_dt_arr = VAR_TO_DT(year, mon, day, hour, min, sec)
Regardless of whether you read the data as strings and use the STR_TO_DT function for conversion, or read the data as integer values and use the VAR_TO_DT function for conversion, the value of the my_dt_arr array is the same. You can easily view the contents of my_dt_arr using the PRINT command:
PRINT, my_dt_arr
Results in the output:
{ 1990 10 2 9 32 0.00000 86946.397 0 }{ 1990 10 2 9 36 0.00000 86946.400 0 }{ 1990 10 2 9 37 0.00000 86946.401 0 }Because the variable my_dt_arr is a structure, curly braces, “{” and “}”, are placed around the output. For more information about the internal organization of date/time structures, refer to Working with Date/Time Data in the PV‑WAVE User’s Guide.
Method 2—Read the File with DC_READ_FIXED
The following statements present another method for reading date/time data into variables (the same data that was used for Method 1). Because this method utilizes the DC_READ_FIXED function, it is able to use a C-style format string to read the data. The data file is repeated below for your convenience:
LAM 10/02/90 09:32:00 10.00 32767
COS 10/02/90 09:36:00 15.89 99999
SNV 10/02/90 09:37:00 14.22 87654
This method automatically handles the string to date and string to time conversion, although it does require that the date/time variable, date1, be predefined as a date/time system structure:
; The system structure definition of date/time is !DT. Date/time
; variables must be defined as !DT structure arrays before being
; used if the date/time data is to be read as such.
date1 = REPLICATE({!DT},3); Explicitly define string, integer, and floating-point vectors.
loc = STRARR(3) & calib = LONARR(3)
decibels = FLTARR(3)
; DC_READ_FIXED handles the opening and closing of the file.
; It transfers the values in “chrono.dat” to the variables in the
; variable list, working from left to right. The variable date1
; appears in the variable list twice, once to read the date data
; and once to read the time data.
status = DC_READ_FIXED("chrono.dat", loc, date1, date1, $
decibels, calib, /Column, Format="%s %8s %8s %f %d", $
Dt_Template=[1,-1])Notice how in this method, the variable date1 is specified twice. Because date1 is defined as a date/time structure, it has predefined tags for the various classes of chronological information. By including date1 in the variable list twice, both the date data and the time data is combined in the same !DT structure, using two different date/time templates (1 for date values and –1 for time values).
For more information about the internal organization of the !DT system structure, refer to Working with Date/Time Data in the PV‑WAVE User’s Guide.
Reading, Sorting, and Printing Tables of Formatted Data
Explicitly formatted I/O has the power and flexibility to handle almost any kind of formatted data. A common use of explicitly formatted I/O is to read and write tables of data.
Example—Reading Data From a Word-Processing Application
Frequently, data files are produced by a word-processing or spreadsheet application program. This example shows how to import this kind of data into variables.
Method 1—Read the File with READF
Consider a data file containing employee data records. Each employee has a name (String—16 columns) and the number of years they have been employed (Integer—3 columns) on the first line. The next two lines contain their monthly salary for the last twelve months. A sample file named bullwinkle.wp with this format might look like the one in Figure 9-3: Sample Data File:
 |
The following statements read data with the above format and produce a summary of its contents:
; Open data file for input.
OPENR, 1, 'bullwinkle.wp'
; Create variables to hold the name, number of years, and monthly
; salaries. Each variable’s type is automatically determined by
; the type of initial value it is given.
name = '' & years = 0 & salary = FLTARR(12)
; Output a heading for the summary.
PRINT, 'Name Years Yearly Salary'
; Output a ruling line for the heading.
PRINT, '--------------------------------------------'; Loop over each employee.
WHILE (NOT EOF(1)) DO BEGIN
; Read the data on the next employee.
READF, 1, name, years, salary, $
Format = "(A16, I3, 2(/, 6F10.2))"
; Output the employee information. Use the TOTAL function
; to compute the yearly salaries from the monthly salaries.
PRINT, Format = "(A16, I5, 5X, F10.2)",$
name, years, TOTAL(salary)
ENDWHILE
CLOSE, 1
The output from executing the statements shown above is illustrated in Table 9-9: Sample Output:
Name | Years | Yearly Salary |
|---|---|---|
Bullwinkle | 10 | 32501.09 |
Boris | 11 | 6805.35 |
Natasha | 10 | 14257.36 |
Rocky | 11 | 32500.50 |
DC_READ_FIXED is not used in this method because the file, as it is shown in Figure 9-3: Sample Data File, is neither a column-organized file or a row-organized file; it falls somewhere in between. In other words, the name and years-of-service data are organized by columns, while the yearly salary data is organized in rows. But the file can be rearranged, as shown below in the next method, and then using DC_READ_FIXED becomes a viable (and time-saving) option.
Method 2—Read the File with DC_READ_FIXED
Suppose the file was much longer than we are able to show in this example, and you wanted to use PV-WAVE’s powerful data connection and table building utilities to read and process the data. If the file was organized a bit differently, DC_READ_FIXED could be used to read the data. Then, the BUILD_TABLE function could be used to quickly organize the data in a table structure. The new file organization is shown in Figure 9-4: Organized Table Structure:
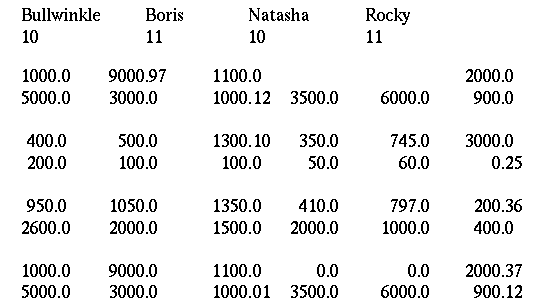 |
The following statements read the data file shown above and display a summary of its contents on the screen:
; Create variables to hold the name, number of years, and monthly
; salaries.
name = STRARR(4) & years = INTARR(4)
salary = FLTARR(12, 4)
; DC_READ_FIXED handles the opening and closing of the file. It
; transfers values in “bullwinkle.wp” to variables in the
; variable list, working from left to right. The two slashes in
; the format string force DC_READ_FIXED to switch to a new record
; in the input file. When reading row-oriented data, each vari
; able is “filled up” before any data is transferred to the next
; variable in the variable list. The value of the Ignore keyword
; insures that all blank lines are skipped instead of being
; interpreted as data.
status = DC_READ_FIXED('bullwinkle.wp', name, years, salary, $
Format= "(4A16, " + "/, I3, 3(10X,I3), /, 48(F7.2, 3X))", $
Ignore=["$BLANK_LINES"]); Print a heading and ruling line for the heading.
PRINT, 'Name Years Yearly Salary'
PRINT, '--------------------------------------------'yearly_salary = FLTARR(4)
; One row at a time, total the monthly salaries.
FOR I = 0,3 DO BEGIN
; Use array subscripting notation to total twelve months of
; salary for each employee.
yearly_salary(I) = TOTAL(salary[*,I])
ENDFOR
; Create table structure, with each information column being an
; individual tag of the structure.
zz = BUILD_TABLE('name, years, yearly_salary'); Print one row at a time.
FOR I = 0,3 DO BEGIN
; Print the employee information. Each column of information
; is now a tag of the zz table.
PRINT, Format="(A16, 3X, I5, 5X, F10.2)", zz(I).name, $
zz(I).years, zz(I).yearly_salary
ENDFOR
note | You do not need to understand structures to work with tables. For a comparison of tables and structures, refer to the Creating and Querying Tables in the PV‑WAVE User’s Guide. |
Just like in Method 1, the output from executing the previous statements shown is:
Name | Years | Yearly Salary |
|---|---|---|
Bullwinkle | 10 | 32501.09 |
Boris | 11 | 6805.35 |
Natasha | 10 | 14257.36 |
Rocky | 11 | 32500.50 |
Now you could easily enter commands to sort the table, using a variety of criteria. Suppose you want to rearrange the table (in descending order) so that the employee with the highest salary is listed first:
by_val = QUERY_TABLE(zz, '* Order By yearly_salary Desc')
; Print one row at a time.
FOR I = 0,3 DO BEGIN
; Print the employee information. Each column of information
; is a tag of the by_val table.
PRINT, Format="(A16, 3X, I5, 5X, F10.2)", by_val(I).name, $
by_val(I).years, by_val(I).yearly_salary
ENDFOR
The output is now sorted in descending order by yearly salary:
Name | Years | Yearly Salary |
|---|---|---|
Bullwinkle | 10 | 32501.09 |
Rocky | 11 | 32500.50 |
Natasha | 10 | 14257.36 |
Boris | 11 | 6805.35 |
Now suppose you want to rearrange the table (in ascending alphabetical order) so that the employees are listed alphabetically:
by_val = QUERY_TABLE(zz, '* Order By name')
; Print one row at a time.
FOR I = 0,3 DO BEGIN
; Print the employee information.
PRINT, Format="(A16, 3X, I5, 5X, F10.2)", by_val(I).name, $
by_val(I).years, by_val(I).yearly_salary
ENDFOR
The output is now sorted in ascending alphabetic order:
Name | Years | Yearly Salary |
|---|---|---|
Boris | 11 | 6805.35 |
Bullwinkle | 10 | 32501.09 |
Natasha | 10 | 14257.36 |
Rocky | 11 | 32500.50 |
For more information about functions for sorting and organizing table structures, and the keywords that can be used inside the QUERY_TABLE sort string, refer to the PV‑WAVE User’s Guide.
Reading Records Containing Multiple Array Elements
Frequently, data is written to files with each record containing single elements of more than one array. For example, a file might contain observations of altitude, pressure, temperature, and velocity, with each line (or record) containing a value for each of the four variables. Data files like this are called record-oriented files, and PV-WAVE offers several different ways to read them, as shown below.
Example 1—Column-oriented FORTRAN Write
A FORTRAN program that writes the data and the PV-WAVE program that reads the data are shown below:
FORTRAN Write
This FORTRAN program writes the data by creating an array with as many columns as there are variables and as many rows as there are elements.
DIMENSION ALT(100), PRES(100), TEMP(100),
C VELO(100)
OPEN (UNIT=1, STATUS='NEW', FILE='aptv.dat')
.
. Other commands go here..
WRITE (1,'(4(1x, G15.5))')
C (ALT(I), PRES(I), TEMP(I), VELO(I), I = 1,100)
END
PV-WAVE Read (Method 1)
The data is read into an array, the array is transposed storing each variable as a row, and each row is extracted and stored in a one-dimensional variable.
; Open file for input.
OPENR, 1, 'aptv.dat'
; Define variable to hold 100 observations of data, 4 values per
; observation.
A = FLTARR(4,100)
; Read the data.
READF, 1, A
; Transpose array so that columns become rows.
A = TRANSPOSE(A)
; Extract altitude, pressure, temperature, and velocity data from
; variable A.
alt = A(*,0) & pres = A(*,1) &
temp = A(*,2) & velo = A(*,3)
; Close the file.
CLOSE, 1
PV-WAVE Read (Method 2)
In this method, the data is read by calling DC_READ_FIXED, one of the DC routines for simplified I/O:
; DC_READ_FIXED transfers values in “aptv.dat” to the variables
; alt, pres, temp, and velo. One value from each record is
; transferred to each variable. DC_READ_FIXED creates the
; variables as floating-point vectors, with a length that matches
; the number of values transferred into the variables.
; DC_READ_FIXED handles the opening and closing of the file.
status = DC_READ_FIXED('aptv.dat', alt, $
pres, temp, velo, /Column, Format="%f")The variables could now be easily placed into a table structure with the following command:
; Create table structure, with each column of information being
; an individual tag of the table.
aptv = BUILD_TABLE('alt, pres, temp, velo')For more information about what can be done with data once it is placed into a table structure, refer to Method 2—Read the File with DC_READ_FIXED, or refer to the PV‑WAVE User’s Guide.
Notice that the variables were not predefined with the FLTARR function, as they were with Method 1. Because the variables were not predefined, DC_READ_FIXED creates them all as one-dimensional floating-point arrays dimensioned to match the number of records in the file. For example, suppose that each column of data in aptv.dat contained 280 values. All four variables (alt, pres, temp, and velo) would be created and dimensioned as 280 element vectors.
Example 2—Row-oriented FORTRAN Write
The same data values may be written without the implied DO list, writing all elements for each variable contiguously and simplifying the FORTRAN write program:
FORTRAN Write
DIMENSION ALT(100), PRES(100), TEMP(100),
C VELO(100)
OPEN (UNIT=1, STATUS='NEW', FILE='aptv.dat')
.
. Other commands go here..
WRITE (1,'(4(1x,G15.5))') ALT, PRES, TEMP,
C VELO
END
PV-WAVE Read (Method 1)
Read the data as an uninterrupted stream of values. In other words, read the file as though it contains row-oriented data.
; Create a floating-point array to hold the data.
alt = FLTARR(100)
; Create more floating-point arrays, all the same size as alt.
pres = alt & temp = alt & velo = alt
; Open file for input.
OPENR, 1, 'aptv.dat'
; Read the data.
READF, 1, alt, pres, temp, velo
; Close the file.
CLOSE, 1
PV-WAVE Read (Method 2)
DC_READ_FIXED can be used to read row-oriented data; in fact, this happens by default when the Column keyword is omitted from the function call. However, when you are reading row-oriented data, the import variables must be pre-dimensioned so that DC_READ_FIXED knows how many values to store in each of the variables included in the variable list:
; Create a floating-point array to hold the data.
alt = FLTARR(100)
; Create more floating-point arrays, all the same size as alt.
pres = alt & temp = alt & velo = alt
; DC_READ_FIXED handles the opening and closing of the file. It
; reads values from aptv.dat and stores them in the variables
; alt, pres, temp, and velo. By default, the data is read as row-
; oriented data. The returned value status can be checked to see
; if the process completed successfully.
status = DC_READ_FIXED('aptv.dat', alt, $
pres, temp, velo, Format="%f")The format string shown in this example (Method 2) may be used only if all of the variables in the variable list are typed as floating-point, because the same C format string is used over and over to read all the data values. For more information on format reversion, (the process of re-using format strings when reading or writing data), refer to "Format Reversion".
note | If the variable list contained other data types besides floating-point, the format string would have to be more specific, such as the one used in the next example. Another alternative is to use DC_READ_FREE (instead of DC_READ_FIXED) to read the file, and then you aren’t required to supply any format string. |
Example 3—Using a FORTRAN Format String to Read Multiple Array Elements
Assume that the data used is the same as that of the previous examples, but a fifth variable, the name of an observer (which is a string), has been added to the variable list. The FORTRAN output routine and PV-WAVE input routine are shown below:
FORTRAN Write
DIMENSION ALT(100), PRES(100), TEMP(100),
C VELO(100)
CHARACTER*10 OBS(100)
OPEN (UNIT = 1, STATUS = 'NEW', FILE =
C 'aptvo.dat')
.
. Other commands go here..
WRITE (1,'(4(1X,G15.5), 2X, A)') (ALT(I),
C PRES(I), TEMP(I), VELO(I), OBS(I), I = 1,100)
END
PV-WAVE Read (Method 1)
This method involves defining the arrays, defining a scalar variable to contain each value in one record, then writing a loop to read each line into the scalars, and finally storing the scalar values into each array:
; Access file. This example reads files containing from 0 to 100
; records.
OPENR, 1, 'aptvo.dat'
; Create a floating-point array to hold the data.
alt = FLTARR(100)
; Create more floating-point arrays, all the same size as alt.
pres = alt & temp = alt & velo = alt
; Define string array.
obs = STRARR(100)
; Define scalar string.
obss = ' '
; Initialize counter.
I = 0
; Beginning of read loop.
WHILE NOT EOF(1) DO BEGIN
; Read scalars; the last one is a string variable, and by
; default, the first four are floating-point variables.
READF, 1, alts, press, temps, velos, obss, $
Format="(4(1X, G15.5), 2X, A10)"
alt(I) = alts & pres(I) = press
temp(I) = temps & velo(I) = velos
; Store in each vector.
obs(I) = obss
; Increment counter and check for too many records.
IF I LE 99 THEN I = I+1 ELSE CLOSE,1 & $
STOP, "Too many records."
ENDWHILE
; Close the file.
CLOSE, 1
If desired, after the file has been read and the number of observations is known, the arrays may be truncated to the correct length using a series of statements similar to:
alt = alt(0:I-1)
The above represents a worst case example. Reading is greatly simplified by writing data of the same type contiguously and by knowing the size of the file. Another alternative is to use Method 2, shown below.
note | One frequently used technique is to include the number of observations in the first record so that when reading the data the size is known. |
PV-WAVE Read (Method 2)
The DC_READ_FIXED function is ideal for situations such as this one, where the columns are treated as different data types or the number of lines or records in the file is not known.
; Define string array; let other variables use default
; floating-point data type.
obs = STRARR(100)
; DC_READ_FREE handles the opening and closing of the file. It
; reads values from aptvo.dat and stores them in the variables
; alt, pres, temp, velo, and obs. The data is being read as column
; oriented data.
; Because Resize was included with the function call, all five
; variables are resizable and redimensioned to match the number
; of values actually transferred from the file. The returned
; value status can be checked to see if the process completed
; successfully.
status = DC_READ_FIXED('aptvo.dat', alt, pres, temp, velo, $
obs, /Column, Format="(4(1X, G15.5), 2X, A10)", $
Resize=[1, 2, 3, 4, 5])Using the STRING Function to Format Data
The STRING function is very similar to the PRINT and PRINTF procedures. You can even think of it as a version of PRINT that places its ASCII output into a string variable instead of a file. If the output is a single line, the result is a scalar string. If the output has multiple lines, the result is a string array, with each element of the array containing a single line of the output.
Example 1—STRING Function without Format Keyword
Three variations using the STRING function are shown below:
abc = STRING([65B,66B,67B])
abc = STRING([byte('A'),byte('B'),byte('C')])abc = STRING('A'+'B'+'C')In all three cases, abc has the same value, the string scalar 'ABC'.
Example 2—STRING Function with Format Keyword
The following statements:
; Create a string array named A.
A = STRING(Format='("The values are:", ' + $
', (I))', INDGEN(5)); Display information about A.
INFO, A
; Print the result.
FOR I = 0, 5 DO PRINT, A(I)
produce the following output:
A STRING = Array(6)
The values are:
0
1
2
3
4
For additional details about the STRING function, see its description in the PV‑WAVE Reference.




