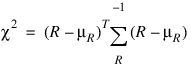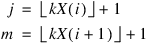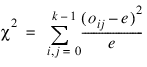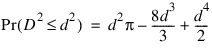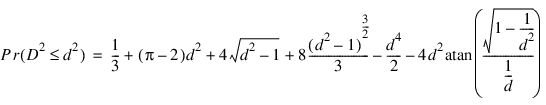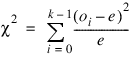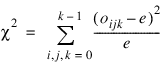RANDOMNESS_TEST Function (PV-WAVE Advantage)
Performs tests for independence and uniformity.
Usage
result = RANDOMNESS_TEST(x, n_run)
Input Parameters
x—One-dimensional array containing the data.
n_run—Length of longest run for which tabulation is desired. For keywords Pairs_Counts, Dsquare_Counts, and Dcube_Counts, n_run stands for the number of equiprobable cells into which the statistics are to be tabulated.
Returned Value
result—The probability of a larger chi-squared statistic for testing the null hypothesis of a uniform distribution.
Input Keywords
Double—If present and nonzero, double precision is used.
Pairs_Lag—The lag to be used in computing the pairs statistic. Keywords Pairs_Lag and Pairs_Counts must be used together.
Output Keywords
Exactly one of the options listed in
Output Keywords is used to specify which test is to be performed.
Runs_Counts—Named variable into which an array of size N_ELEMENTS(x) containing the counts of the number of runs up each length is stored. The Runs Test is the default test, however, to return the counts and covariances, the Runs_Counts keyword must be used. Keywords Runs_Counts and Covariances must be used together. Keywords Runs_Counts, Pairs_Counts, Dsquare_Counts, and Dcube_Counts can not be used together.
Covariances—Named variable into which an array of size N_ELEMENTS(x) by N_ELEMENTS(x) containing the variances and covariances of the counts is stored. Keywords Runs_Counts and Covariances must be used together.
Pairs_Counts—Named variable into which an array of size n_run by n_run containing the count of the number of pairs in each cell is stored. The lag to be used in computing the pairs statistic is stored in Pairs_Lag. Pairs (X(i), X(i + Pairs_Lag)) for i = 0, ..., N – Pairs_Lag – 1 are tabulated, where N is the total sample size. Keywords Pairs_Counts and Pairs_Lag must be used together. Keywords Pairs_Counts, Runs_Counts, Dsquare_Counts, and Dcube_Counts can not be used together.
Dsquare_Counts—Named variable into which an array of length n_run containing the tabulations for the d2 test is stored. Keywords Dsquare_Counts, Runs_Counts, Pairs_Counts, and Dcube_Counts can not be used together
Dcube_Counts—Named variable into which an array of length n_run by n_run by n_run containing the tabulations for the triplets test is stored. Keywords Runs_Counts, Pairs_Counts, Dsquare_Counts, and Dcube_Counts can not be used together.
Chisq—Named variable into which the Chi-squared statistic for testing the null hypothesis of a uniform distribution is stored.
Df—Named variable into which the degrees of freedom for chi-squared is stored.
Runs_Counts is specified
Runs_Expect—Named variable into which an array of length n_run containing the expected number of runs of each length is expected is stored. This keyword is optional if Runs_Counts is used.
Pairs_Counts, Dsquare_Counts, or Dcube_Counts is specified:
Expect—Named variable into which the expected number of counts for each cell is stored. This keyword is optional only if one of the keywords Pairs_Counts, Dsquare_Counts, or Dcube_Count is used. Keywords Runs_Counts and Expect can not be used together.
Discussion
Runs Up Test
Function RANDOMNESS_TEST performs one of four different tests for randomness. Input keyword Runs_Counts computes statistics for the runs up test. Runs tests are used to test for cyclical trend in sequences of random numbers. If the runs down test is desired, each observation should first be multiplied by –1 to change its sign, and Runs_Counts used with the modified vector of observations.
Runs_Counts first tallies the number of runs up (increasing sequences) of each desired length. For i = 1, ..., r – 1, where r = n_run, Runs_Counts(i) contains the number of runs of length i. Runs_Counts(n_run) contains the number of runs of length n_run or greater. As an example of how runs are counted, the sequence (1, 2, 3, 1) contains 1 run up of length 3, and one run up of length 1.
After tallying the number of runs up of each length, Runs_Counts computes the expected values and the covariances of the counts according to methods given by Knuth (1981, pages 65(67). Let R denote a vector of length n_run containing the number of runs of each length so that the ith element of R, ri, contains the count of the runs of length i. Let ΣR denote the covariance matrix of R under the null hypothesis of randomness, and let μR denote the vector of expected values for R under this null hypothesis, then an approximate chi-squared statistic with n_run degrees of freedom is given as:
In general, the larger the value of each element of μR, the better the chi-squared approximation.
Pairs Test
Pairs_Counts computes the pairs test (or the Good’s serial test) on a hypothesized sequence of uniform (0,1) pseudorandom numbers. The test proceeds as follows. Subsequent pairs (X(i), X(i + Pairs_Lag)) are tallied into a k × k matrix, where k = n_run. In this tally, element (j, m) of the matrix is incremented, where:
where
l =
Pairs_Lag, and the notation
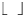
represents the greatest integer function,
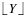
is the greatest integer less than or equal to
Y, where
Y is a real number. If
l = 1, then
i = 1, 3, 5, ...,
n – 1. If
l > 1, then
i = 1, 2, 3, ...,
n –
l, where
n is the total number of pseudorandom numbers input on the current usage of
Pairs_Counts (
i.e.,
n = N_ELEMENTS(
x)).
Given the tally matrix in Pairs_Counts, chi-squared is computed as:
where e = Σoij/k2, and oij is the observed count in cell (i, j) (oij = Pairs_Counts (i, j)).
Because pair statistics for the trailing observations are not tallied on any call, the user should use Pairs_Counts with N_ELEMENTS(x) as large as possible. For Pairs_Lag < 20 and N_ELEMENTS(x) = 2000, little power is lost.
d2 Test
Dsquare_Counts computes the d2 test for succeeding quadruples of hypothesized pseudorandom uniform (0, 1) deviates. The d2 test is performed as follows. Let X1, X2, X3, and X4 denote four pseudorandom uniform deviates, and consider:
D2 = (X3 – X1)2 + (X4 – X2)2
The probability distribution of D2 is given as:
when D2 ≤1, where π denotes the value of pi. If D2 > 1, this probability is given as:
See Gruenberger and Mark (1951) for a derivation of this distribution.
For each succeeding set of 4 pseudorandom uniform numbers input in x, d2 and the cumulative probability of d2 (Pr(D2 ≤ d2)) are computed. The resulting probability is tallied into one of k = n_run equally spaced intervals.
Let n denote the number of sets of four random numbers input (n = the total number of observations/4). Then, under the null hypothesis that the numbers input are random uniform (0, 1) numbers, the expected value for each element in Dsquare_Counts is e = n/k. An approximate chi-squared statistic is computed as:
where oi = Dsquare_Counts(i) is the observed count. Thus, χ2 has k – 1 degrees of freedom, and the null hypothesis of pseudorandom uniform (0, 1) deviates is rejected if χ2 is too large. As n increases, the chi-squared approximation becomes better. A useful generalization is that e > 5 yields a good chi-squared approximation.
Triplets Test
Dcube_Counts computes the triplets test on a sequence of hypothesized pseudorandom uniform(0, 1) deviates. The triplets test is computed as follows: Each set of three successive deviates, X1, X2, and X3, is tallied into one of m3 equal sized cubes, where m = n_run. Let i = [mX1] + 1, j = [mX2] + 1, and k = [mX3] + 1. For the triplet (X1, X2, X3), Dcube_Counts(i, j, k) is incremented.
Under the null hypothesis of pseudorandom uniform(0, 1) deviates, the m3 cells are equally probable and each has expected value e = n/m3, where n is the number of triplets tallied. An approximate chi-squared statistic is computed as:
where oijk = Dcube_Counts(i, j, k).
The computed chi-squared has m3– 1 degrees of freedom, and the null hypothesis of pseudorandom uniform (0, 1) deviates is rejected if χ2 is too large.
Example 1
The following example illustrates the use of the runs test on 104 pseudo-random uniform deviates. In the example, 2000 deviates are generated for each use of Runs_Counts. Since the probability of a larger chi-squared statistic is 0.1872, there is no strong evidence to support rejection of this null hypothesis of randomness.
PRO print_results, n_run, num, rc, re, cov, chisq, df, p
PRINT, ' runs_count'
PRINT, num + 1, Format = '(6I5)'
PRINT, rc, Format = '(6I5)'
PRINT
PRINT, ' runs_expect'
PRINT, num + 1, Format = '(6I7)'
PRINT, re, Format = '(6F7.1)'
PRINT
PRINT, ' covariances'
PRINT, num + 1, Format = '(7X, 6I8)'
FOR i=0L, n_run - 1 DO $
PRINT, num(i) + 1, cov(i, *), Format = '(I8, 6F8.1)'
PRINT
PRINT, 'chisq =', chisq
PRINT, 'df =', df
PRINT, 'pvalue =', p
END
nran = 10000
n_run = 6
num = INDGEN(n_run)
RANDOMOPT, set = 123457
x = RANDOM(nran, /Uniform)
p = RANDOMNESS_TEST(x, n_run, Runs_Counts = rc, $
Covariances = cov, Chisq = chisq, Df = df, Runs_Expect = re)
print_results, n_run, num, rc,re,cov,chisq, df, p
This results in the following output:
runs_count
1 2 3 4 5 6
1709 2046 953 260 55 4
runs_expect
1 2 3 4 5 6
1667.3 2083.4 916.5 263.8 57.5 11.9
covariances
1 2 3 4 5 6
1 1278.2 -194.6 -148.9 -71.6 -22.9 -6.7
2 -194.6 1410.1 -490.6 -197.2 -55.2 -14.4
3 -148.9 -490.6 601.4 -117.4 -31.2 -7.8
4 -71.6 -197.2 -117.4 222.1 -10.8 -2.6
5 -22.9 -55.2 -31.2 -10.8 54.8 -0.6
6 -6.7 -14.4 -7.8 -2.6 -0.6 11.7
chisq = 8.76515
df = 6.00000
pvalue = 0.187223
Example 2
The following example illustrates the calculations of the Pairs_Counts statistics when a random sample of size 104 is used and the Pairs_Lag is 1. The results are not significant.
PRO print_results, n_run, num, pc, expect, chisq, df, p
PRINT, ' pairs_count'
PRINT, num + 1, Format = '(5X, 10I5)'
FOR i=0L, n_run - 1 DO $
PRINT, num(i) + 1, pc(i, *), Format = '(I5, 10I5)'
PRINT
PRINT, 'expect =', expect
PRINT, 'chisq =', chisq
PRINT, 'df =', df
PRINT, 'pvalue =', p
END
nran = 10000
n_run = 10
num = INDGEN(n_run)
lag = 5
RANDOMOPT, set = 123467
x = RANDOM(nran, /Uniform)
p = RANDOMNESS_TEST(x, n_run, Pairs_Counts = pc, $
Pairs_Lag = lag, Chisq = chisq, $
Df = df, Expect = expect)
print_results, n_run, num, pc, expect, chisq, df, p
This results in the following output:
pairs_count
1 2 3 4 5 6 7 8 9 10
1 112 82 95 118 103 103 113 84 90 74
2 104 106 109 108 101 98 102 92 109 88
3 88 111 86 106 112 79 103 105 106 101
4 91 110 108 92 88 108 113 93 105 114
5 104 105 103 104 101 94 96 87 93 104
6 98 104 103 104 79 89 92 104 92 100
7 103 91 97 101 116 83 118 118 106 99
8 105 105 111 91 93 82 100 104 110 89
9 92 102 82 101 94 128 102 110 125 98
10 79 99 103 98 104 101 93 93 98 105
expect = 99.9500
chisq = 104.860
df = 99.0000
pvalue = 0.324242
Example 3
In the following example, 2000 observations generated using the routine RANDOM are input to Dsquare_Counts in one call. In the example, the null hypothesis of a uniform distribution is not rejected.
PRO print_results, n_run, num, dc, expect, chisq, df, p
PRINT, ' dsquare_counts'
PRINT, num + 1, Format = '(6I5)'
PRINT, dc, Format = '(6I5)'
PRINT
PRINT, 'expect =', expect
PRINT, 'chisq =', chisq
PRINT, 'df =', df
PRINT, 'pvalue =', p
END
nran = 2000
n_run = 6
num = INDGEN(n_run)
RANDOMOPT, set = 123457
x = RANDOM(nran, /Uniform)
p = RANDOMNESS_TEST(x, n_run, Chisq = chisq, Df = df, $
Expect = expect, Dsquare_Counts = dc)
print_results, n_run, num, dc, expect, chisq, df, p
This results in the following output:
dsquare_counts
1 2 3 4 5 6
87 84 78 76 92 83
expect = 83.3333
chisq = 2.05600
df = 5.00000
pvalue = 0.841343
Example 4
In the following example, 2001 deviates generated by the routine RANDOM are input to Dcube_Counts, and tabulated in 27 equally sized cubes. In the example, the null hypothesis is not rejected.
PRO print_results, n_run, num, dc, expect, chisq, df, p
FOR j=0L, n_run - 1 DO BEGIN
PRINT, ' dcube_counts'
PRINT, num + 1, Format = '(5X, 3I5)'
FOR i=0L, n_run - 1 DO $
PRINT, num(i) + 1, dc(j, i, *), Format = '(I5, 3I5)'
PRINT
ENDFOR
PRINT, 'expect =', expect
PRINT, 'chisq =', chisq
PRINT, 'df =', df
PRINT, 'pvalue =', p
END
nran = 2001
n_run = 3
num = INDGEN(n_run)
RANDOMOPT, set = 123457
x = RANDOM(nran, /Uniform)
p = RANDOMNESS_TEST(x, n_run, Chisq = chisq, Df = df, $
Expect = expect, Dcube_Counts = dc)
print_results, n_run, num, dc, expect, chisq, df, p
This results in the following output:
dcube_counts
1 2 3
1 26 27 24
2 20 17 32
3 30 18 21
dcube_counts
1 2 3
1 20 16 26
2 22 22 27
3 30 24 26
dcube_counts
1 2 3
1 28 30 22
2 23 24 22
3 33 30 27
expect = 24.7037
chisq = 21.7631
df = 26.0000
pvalue = 0.701585
Version 2017.0
Copyright © 2017, Rogue Wave Software, Inc. All Rights Reserved.