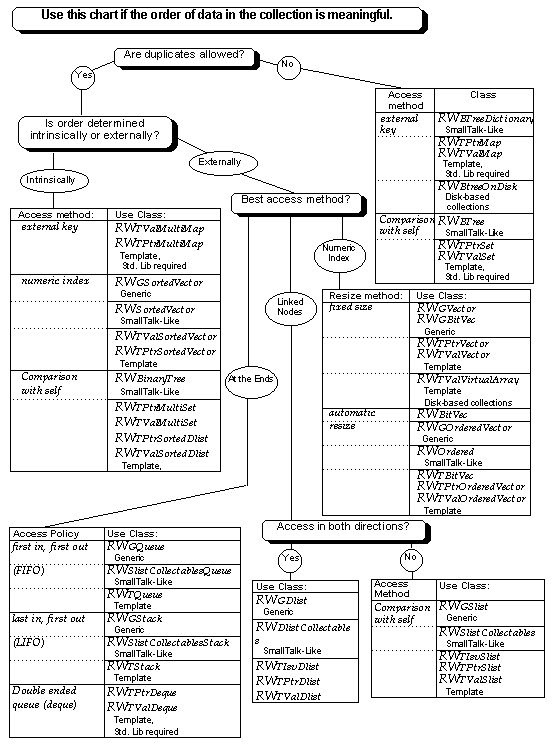
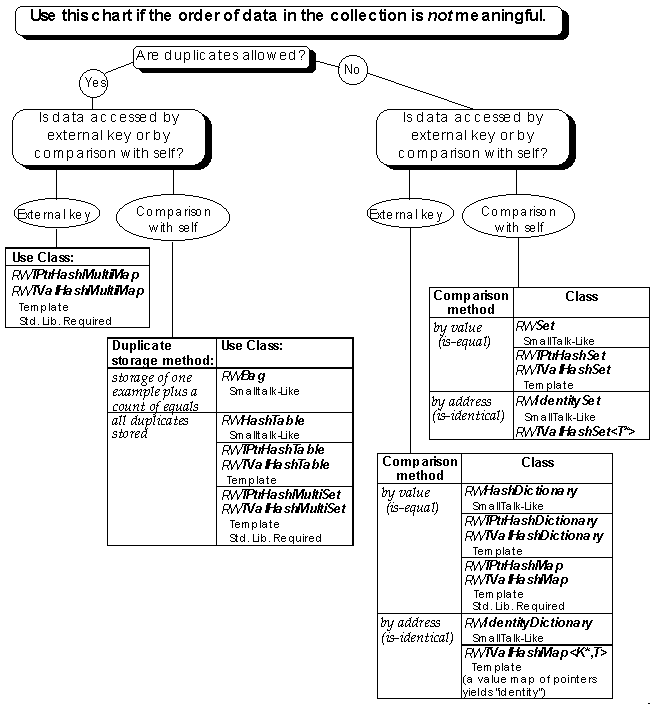
The decision tree diagram includes questions about the data you plan to store in your collection. By traversing the tree you can quickly see which Tools.h++ collection classes will best suit your data and programming project.
The questions that appear on the decision tree are brief, so that the diagram will be easy to read. The following questions expand upon the questions in the decision tree.
Is the order of data in the collection meaningful? Some collections allow you to control the location of data within the collection. For example, arrays or vectors, and linked lists present data in order. If you need to access data in a particular order, or based on a numeric index, then order is meaningful.
Are duplicate entries allowed? Some collections, usually called sets, will not allow you to insert an item equal to an item that is already in the collection. Other collections do permit duplicates, and have various ways to hold multiple matching items. Tools.h++ collections provide mechanisms for both checking for duplication and holding the duplicates.
Is the order determined intrinsically or externally? If data within the collection is controlled by the way you insert it, we say that the order is determined externally. For example, a vector, or a linked list is externally ordered. If the data is stored at a place determined by an algorithm used by the collection, then the ordering is intrinsic. For example, a sorted vector, or a balanced tree has intrinsic ordering.
Is data accessed by an external key? If you access a value based on a key that is not the same as the value, we say that data is accessed by an external key. For example, a "phone list" associates data, in the form of telephone numbers, with keys, in the form of names. Conversly, a list of committee members is simply a set of data in the form of names. You do not need a key to get at the information.
Is data accessed by a numeric index? Objects stored in an array or vector are accessed by numeric index. For example, you access an object at location 12 by using the numeric index "12" to find it.
Is data accessed by "comparison with self?" Data that is stored with neither an explicit index nor an explicit key can be found by looking for a match between what you need to find and what is contained. The list of committee members mentioned in item 4 is and example of this type of data. Sets or bags are examples of collections that are accessed by comparison with self.
When data is accessed by comparison with self, it is also necessary to know what kind of match is used: matching may be based on equality, which directly compares one object with another, or based on identity, which compares object addresses to see if the objects are the same.
Is the best method of access by following linked nodes? Collections that make use of linked nodes are usually called lists. Lists provide quick access to data at each end of the collection, and allow you to insert data efficiently into the middle of the collection. However, if you need repeated access to data in the middle of the collection, lists are not as efficient as some other collections.
Will most of your access to data be at the ends of a collection? There are many occasions when you need to handle an unknown amount of data, but most of that data handling will apply to data that was most recently or least recently put into the collection. A collection that is particularly efficient at handling data that was most recently added is said to have a "last in, first out" policy. A last in, first out (LIFO) container is a stack. A collection that handles the data in a "first in first out" (FIFO) manner is called a queue. Finally, a collection that allows efficient access to both the most recently and least recently added data is called a deque, or double ended queue.
For linked lists --- Do you need to access the data from only one end of the list , or from both ends? Singly-linked lists are smaller, but they allow access only from the "front" of the list. Doubly-linked lists have a more flexible access policy, but at the cost of requiring an additional pointer for every stored object.
For collections that are accessed by numeric index --- Do you need the collection to automatically resize? If you know the maximum number of items that will be stored in the collection, you can make insertion and removal slightly more efficient by choosing a collection with a fixed size. On the other hand, if you need to allow for nearly unlimited expansion, you should choose a collection that will automatically adjust itself to the amount of data it is currently storing.
Which collection you choose will depend of many things (not the least of which will be your experience and intuition). In addition to the decision tree, the following questions will also influence your choice of container.
Do I need to maintain a single object in multiple collections? Use a pointer-based collection.
Am I collecting objects that are very expensive to copy? Use a pointer-based collection.
Is there no compelling reason to use a pointer-based collection? Use a value-based collection.
Do I want to control the order of the objects within the collection externally? Use a sequential collection such as a vector or list.
Should the items within the collection be mutable (not fixed) after they are inserted? Use a sequential or mapping (dictionary) collection. Maps and dictionaries have immutable keys but mutable values.
Would I prefer that the collection maintain its own order based on object comparison? Use a set, map, or sorted collection.
Do I wish to access objects within the collection based on a numerical index? Use a sequential or sorted collection.
Do I need to find values based on non-numeric keys? Use a map or dictionary.
Would I prefer to access objects within the collection by supplying an object for comparison? Use a set, map or hash-based collection.
Am I willing to forego meaningful ordering, and use some extra memory in return for constant-time look-up by key? Use a hash-based collection.
Do I need fast lookup and insertion in a collection that grows or shrinks to meet the current need? Use a b-tree, or an associative container based on the new Standard C++ Library.
Do I need access the data without bringing it all into memory? Use RWBTreeOnDisk or RWTValVirtualArray.