Naive Bayes Overview
Classification problems are characterized by a need to classify unknown patterns or data into one of m categories based upon the values of k attributes x1, x2, ..., xk. There are many algorithms for solving classification problems including discriminant analysis, neural networks and Naive Bayes. Each algorithm has its strengths and weaknesses. Discriminant analysis is robust but it requires x1, x2, ..., xk to be continuous, and since it uses a simple linear equation for the discriminant function, its error rate can be higher than the other algorithms. See the DISCR_ANALYSIS Procedure.
Neural Networks provides a linear or non-linear classification algorithm that accepts both nominal and continuous input attributes. However, network training can be unacceptably slow for problems with a larger number of attributes, typically when k >1000. Naive Bayes, on the other hand, is a simple algorithm that is very fast. A Naive Bayes classifier can be trained to classify patterns involving thousands of attributes and applied to thousands of patterns. As a result, Naive Bayes is a preferred algorithm for text mining and other large classification problems. However, its computational efficiency comes at a price. The error rate for a Naive Bayes classifier is typically higher than the equivalent Neural Network classifier, although it is usually low enough for many applications such as text mining.
If C is the classification attribute and XT={x1, x2, ..., xk} is the vector valued array of input attributes, the classification problem simplifies to estimating the conditional probability P(c|X) from a set of training patterns. The Bayes rule states that this probability can be expressed as the ratio:

where c is equal to one of the target classes 0, 1, ..., n_classes – 1. In practice, the denominator of this expression is constant across all target classes since it is only a function of the given values of X. As a result, the Naive Bayes algorithm does not expend computational time estimating P(X = {x1, x2, ..., xk}) for every pattern. Instead, a Naive Bayes classifier calculates the numerator P(C= c)P(X = {x1, x2, ..., xk}|C= c) for each target class and then classifies X to the target class with the largest value, i.e.,
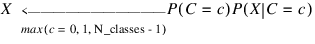
The classifier simplifies this calculation by assuming conditional independence:
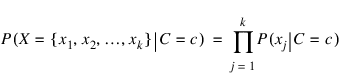
This is equivalent to assuming that the values of the input attributes, given C, are independent of one another, i.e.:
P(xi|xj, C= c) = P(xi|C= c), for all i ≠ j
In real world data this assumption rarely holds, yet in many cases this approach results in surprisingly low classification error rates. Thus, the estimate of P(C= c|X = {x1, x2, ..., xk}) from a Naive Bayes classifier is generally an approximation, classifying patterns based upon the Naive Bayes algorithm can have acceptably low classification error rates.
The NAIVE_BAYES_TRAINER Function is used to train a classifier from a set of training patterns that contains patterns with values for both the input and target attributes. This routine stores the trained classifier into an nb_classifier data structure.
Classifications of new patterns with unknown classifications can be predicted by passing the trained classifier data structure, nb_classifier, to the NAIVE_BAYES_CLASSIFICATION Function.




