CLUSTER_HIERARCHICAL Procedure
Performs a hierarchical cluster analysis given a distance matrix.
Usage
CLUSTER_HIERARCHICAL, dist
Input Parameters
dist—An npt by npt symmetric matrix, where npt is the number of data points to be clustered, containing the distance (or similarity) matrix. dist is a symmetric matrix. On input, only the upper triangular part needs to be present. CLUSTER_HIERARCHICAL saves the upper triangular part of dist in the lower triangle. On return from CLUSTER_HIERARCHICAL, the upper triangular part of dist is restored, and the matrix is made symmetric.
Input Keywords
Double—If present and nonzero, double precision is used.
Method—The clustering method to be used. Default: Method = 0.
Transformation—The method to be used for clustering. Default: Transformation = 0.
Output Keywords
Clevel—Array of length npt – 1 containing the level at which the clusters are joined. Clevel(k – 1) contains the distance (or similarity) level at which cluster npt + k was formed. If the original data in dist was transformed via the Transformation keyword, the inverse transformation is applied to the values in Clevel prior to exit from CLUSTER_HIERARCHICAL.
Clson—Array of length npt – 1 containing the left sons of each merged cluster. Cluster npt + k is formed by merging clusters Clson(k – 1) and Crson(k – 1).
Crson—Array of length npt – 1 containing the right sons of each merged cluster. Cluster npt + k is formed by merging clusters Clson(k – 1) and Crson(k – 1).
Discussion
CLUSTER_HIERARCHICAL conducts a hierarchical cluster analysis based upon the distance matrix. Only the upper triangular part of the matrix dist is required as input to CLUSTER_HIERARCHICAL.
Hierarchical clustering in CLUSTER_HIERARCHICAL proceeds as follows. Initially, each data point is considered to be a cluster, numbered 1 to
n = npt.
n = npt.
1. If the data matrix contains similarities, they are converted to distances by the method specified by Transformation. Set k = 1.
2. A search is made of the distance matrix to find the two closest clusters. These clusters are merged to form a new cluster, numbered n + k. The cluster numbers of the two clusters joined at this stage are saved in Crson and Clson, and the distance measure between the two clusters is stored in Clevel.
3. Based upon the method of clustering, updating of the distance measure in the row and column of dist corresponding to the new cluster is performed.
4. Set k = k + 1. If k < n, go to Step 2.
The five methods differ primarily in how the distance matrix is updated after two clusters have been joined. The Method keyword specifies how the distance of the cluster just merged with each of the remaining clusters will be updated. CLUSTER_HIERARCHICAL allows five methods for computing the distances. To understand these measures, suppose in the following discussion that clusters “A” and “B” have just been joined to form cluster “Z”, and interest is in computing the distance of Z with another cluster called “C”.
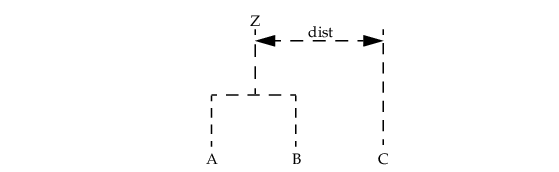
Method | Method |
|---|---|
0 | Single linkage method. The distance from Z to C is the minimum of the distances (A to C, B to C). |
1 | Complete linkage method. The distance from Z to C is the maximum of the distances (A to C, B to C). |
2 | Average-distance-within-clusters method. The distance from Z to C is the average distance of all objects that would be within the cluster formed by merging clusters Z and C. This average may be computed according to formulas given by Anderberg (1973, page 139). |
3 | Average-distance-between-clusters method. The distance from Z to C is the average distance of objects within cluster Z to objects within cluster C. This average may be computed according to methods given by Anderberg (1973, page 140). |
4 | Ward’s method. Clusters are formed so as to minimize the increase in the within-cluster sums of squares. The distance between two clusters is the increase in these sums of squares if the two clusters were merged. A method for computing this distance from a squared Euclidean distance matrix is given by Anderberg (1973, pages 142–145). |
In general, single linkage will yield long thin clusters while complete linkage will yield clusters that are more spherical. Average linkage and Ward’s linkage tend to yield clusters that are similar to those obtained with complete linkage.
CLUSTER_HIERARCHICAL produces a unique representation of the binary cluster tree via the following three conventions; the fact that the tree is unique should aid in interpreting the clusters. First, when two clusters are joined and each cluster contains two or more data points, the cluster that was initially formed with the smallest level (in clevel) becomes the left son. Second, when a cluster containing more than one data point is joined with a cluster containing a single data point, the cluster with the single data point becomes the right son. Finally, when two clusters containing only one object are joined, the cluster with the smallest cluster number becomes the right son.
Comments
1. The clusters corresponding to the original data points are numbered from 1 to npt. The npt – 1 clusters formed by merging clusters are numbered npt + 1 to npt + (npt – 1).
2. Raw correlations, if used as similarities, should be made positive and transformed to a distance measure. One such transformation can be performed by specifying the Transformation keyword, with Transformation = 2 in CLUSTER_HIERARCHICAL.
3. The user may cluster either variables or observations in CLUSTER_HIERARCHICAL since a dissimilarity matrix, not the original data, is used. DISSIMILARITIES may be used to compute the matrix dist for either the variables or observations.
Example
In the following example, the average distance within clusters method is used to perform a hierarchical cluster analysis of the Fisher iris data. The STATDATA function is first used to obtain the Fisher iris data. The example is typical in that after the program obtains the data, function DISSIMILARITIES computes the distance matrix (dist) prior to calling CLUSTER_HIERARCHICAL.
; Create the input data
x = STATDATA(3)
; Create the distance matrix
dist = DISSIMILARITIES(x,ind=[1,2,3,4], scale=1)
; Call the CLUSTER_HIERARCHICAL routine using the
; 'Complete linkage(maximum distance)' method.
CLUSTER_HIERARCHICAL, dist, $
clevel=clevel, $
clson=clson, $
crson=crson, method=2
; Display the results
cl = FLTARR(10)
ic = LONARR(10)
icr = LONARR(10)
j = 0L
; Subset the output for display
FOR i=0L,149,15 DO BEGIN & $
cl(j) = clevel(i) & $
ic(j) = clson(i) & $
icr(j) = crson(i) & $
j = j+1 & $
ENDFOR
PRINT,""
PRINT," OUTPUT"
PRINT," ------------------"
PRINT, cl, Format="(10F6.2)"
PRINT, ic, Format="(10I6)"
PRINT, icr, Format="(10I6)"
Output
OUTPUT
------------------
0.00 0.17 0.23 0.27 0.31 0.37 0.41 0.48 0.60 0.78
143 153 17 140 53 198 186 218 261 249
102 29 6 113 51 91 212 243 266 262




