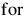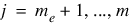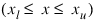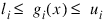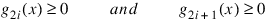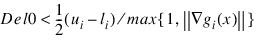CONSTRAINED_NLP Function (PV-WAVE Advantage)
Solves a general nonlinear programming problem using a sequential equality constrained quadratic programming method.
Usage
result = CONSTRAINED_NLP (f, m, n)
Input Parameters
f—Scalar string specifying a user-supplied procedure to evaluate the objective function and constraints at a given point.
 x
x—One dimensional array at which the objective function or a constraint is evaluated.
iact—Integer indicating whether evaluation of the objective function is requested or evaluation of a constraint is requested. If
iact is zero, then an objective function evaluation is requested. If
iact is nonzero then the value if
iact indicates the index of the constraint to evaluate.
result—If
iact is zero, then
result is the computed objective function at the point
x. If iact is nonzero, then result is the requested constraint value at the point x. ierr—Integer variable. On input
ierr is set to 0. If an error or other undesirable condition occurs during evaluation, then
ierr should be set to 1. Setting
ierr to 1 will result in the step size being reduced and the step being tried again. (If
ierr is set to 1 for
Xguess, then an error is issued.)
m—Total number of constraints.
n—Number of variables.
Returned Value
result—The solution of the nonlinear programming problem.
Input Keywords
Double—If present and nonzero, double precision is used.
Meq—Number of equality constraints. Default: Meq = m
Ibtype—Scalar indicating the types of bounds on variables.
0
—User supplies all the bounds.
1
—All variables are non-negative.
2
—All variables are nonpositive.
3
—User supplies only the bounds on first variable; all other variables have the same bounds.
Default: no bounds are enforced
Xguess—A
rray with n components containing an initial guess of the computed solution. Default:
Xguess =
X, with the smallest value of
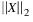
that satisfies the bounds.
Grad—Scalar string specifying a user-supplied procedure to evaluate the gradients at a given point. The procedure specified by Grad has the following parameters
x—One dimensional array at which the gradient of the objective function or gradient of a constraint is evaluated.
iact—Integer indicating whether evaluation of the gradient of the objective function is requested or evaluation of gradient of a constraint is requested. If
iact is zero, then an objective function evaluation is requested. If
iact is nonzero then the value if
iact indicates the index of the constraint to evaluate.
result—If
iact is zero, then
result is the computed gradient of the objective function at the point
x. If iact is nonzero, then result is the gradient of the requested constraint value at the point x. Itmax—Maximum number of iterations allowed. Default: Itmax = 200
Tau0—A universal bound describing how much the unscaled penalty-term may deviate from zero.
CONSTRAINED_NLP assumes that within the region described by:
all functions may be evaluated safely. The initial guess, however, may violate these requirements. In that case an initial feasibility improvement phase is run by CONSTRAINED_NLP until such a point is found. A small Tau0 diminishes the efficiency of CONSTRAINED_NLP, because the iterates then will follow the boundary of the feasible set closely. Conversely, a large Tau0 may degrade the reliability of the code. Default Tau0 = 1.0
Del0—In the initial phase of minimization a constraint is considered binding if:
Good values are between 0.01 and 1.0. If Del0 is chosen too small then identification of the correct set of binding constraints may be delayed. Contrary, if Del0 is too large, then the method will often escape to the full regularized SQP method, using individual slack variables for any active constraint, which is quite costly. For well-scaled problems Del0 = 1.0 is reasonable. Default: Del0 = .5* Tau0
Smallw—Scalar containing the error allowed in the multipliers. For example, a negative multiplier of an inequality constraint is accepted (as zero) if its absolute value is less than Smallw. Default: Smallw = exp(2*log(eps/3)) where eps is the machine precision.
Delmin—Scalar which defines allowable constraint violations of the final accepted result. Constraints are satisfied if |gi(x)| is less than or equal to delmin, and gi(x) is greater than or equal to (–Delmin) respectively. Default: Delmin = min(Del0/10, max(Epsdif, min(Del0/10, max(1.0e–6* Del0, Smallw))
Scfmax—Scalar containing the bound for the internal automatic scaling of the objective function. Default: Scfmax = 1.0e4
Xlb—Named variable, containing a one-dimensional array with n components, containing the lower bounds on the variables. (Input, if Ibtype = 0; Output, if Ibtype = 1 or 2; Input/Output, if Ibtype = 3). If there is no lower bound on a variable, the corresponding Xlb value should be set to negative machine infinity. Default: no lower bounds are enforced on the variables
Xub—Named variable, containing a one-dimensional array with n components, containing the upper bounds on the variables. (Input, if Ibtype = 0; Output, if Ibtype = 1 or 2; Input/Output, if Ibtype = 3). If there is no upper bound on a variable, the corresponding Xub value should be set to positive machine infinity. Default: no upper bounds are enforced on variables
Keywords Valid Only if Keyword Grad is not Supplied
Difftype—Type of numerical differentiation to be used. Default:
Difftype = 1
1—Use a forward difference quotient with discretization stepsize 0.1 (
epsfcn1/2)
component-wise relative.2—Use the symmetric difference quotient with discretization stepsize 0.1 (
epsfcn1/3) component-wise relative.
3—Use the sixth order approximation computing a Richardson extrapolation of three symmetric difference quotient values. This uses a discretization stepsize 0.01 (
epsfcn1/7).
Xscale—Vector of length n setting the internal scaling of the variables. The initial value given and the objective function and gradient evaluations however are always in the original unscaled variables. The first internal variable is obtained by dividing values x(I) by Xscale(I).
In the absence of other information, set all entries to 1.0. Default: Xscale(*) = 1.0
Epsdif—Relative precision in gradients. Default: Epsdif = eps where eps is the machine precision.
Epsfcn—Relative precision of the function evaluation routine. Default: Epsfcn = eps where eps is the machine precision.
Taubnd—Amount by which bounds may be violated during numerical differentiation. Bounds are violated by taubnd (at most) only if a variable is on a bound and finite differences are taken for gradient evaluations. Default: Taubnd = 1.0
Output Keywords
Obj—Name of a variable into which a scalar containing the value of the objective function at the computed solution is stored.
Description
The routine CONSTRAINED_NLP provides an interface to a licensed version of subroutine DONLP2, a code developed by Peter Spellucci (1998). It uses a sequential equality constrained quadratic programming method with an active set technique, and an alternative usage of a fully regularized mixed constrained subproblem in case of nonregular constraints (for example, linear dependent gradients in the “working sets”). It uses a slightly modified version of the Pantoja-Mayne update for the Hessian of the Lagrangian, variable dual scaling and an improved Armjijo-type stepsize algorithm. Bounds on the variables are treated in a gradient-projection like fashion. Details may be found in the following two papers:
P. Spellucci: An SQP method for general nonlinear programs using only equality constrained subproblems. Math. Prog. 82, (1998), 413-448.
P. Spellucci: A new technique for inconsistent problems in the SQP method. Math. Meth. of Oper. Res. 47, (1998), 355-500. (published by Physica Verlag, Heidelberg, Germany).
The problem is stated as follows:
subject to:
Although default values are provided for input keywords, it may be necessary to adjust these values for some problems. Through the use of keywords, CONSTRAINED_NLP allows for several parameters of the algorithm to be adjusted to account for specific characteristics of problems. The DONLP2 Users Guide provides detailed descriptions of these parameters as well as strategies for maximizing the performance of the algorithm. The DONLP2 Users Guide is available in the “manuals” subdirectory of the main WAVE product installation directory. In addition, the following are guidelines to consider when using CONSTRAINED_NLP.
A good initial starting point is very problem specific and should be provided by the calling program whenever possible. For more details, see keyword
Xguess.
Gradient approximation methods can have an effect on the success of CONSTRAINED_NLP. Selecting a higher order approximation method may be necessary for some problems. For more details, see keyword
Difftype.
If a two-sided constraint:
is transformed into two constraints:
then choose:
or at least try to provide an estimate for that value. This will increase the efficiency of the algorithm. For more details, see keyword Del0.
The parameter
ierr provided in the interface to the user supplied function
f can be very useful in cases when evaluation is requested at a point that is not possible or reasonable. For example, if evaluation at the requested point would result in a floating point exception, then setting
ierr to 1 and returning without performing the evaluation will avoid the exception. CONSTRAINED_NLP will then reduce the stepsize and try the step again. Note, if
ierr is set to 1 for the initial guess, then an error is issued.
Example
The problem:
min F(x) = (x1 – 2)2 + (x2 – 1)2
subject to:
g1(x) = x1 – 2x2 + 1 = 0
g2(x) = –x21 /4 – x22 + 1 ≥ 0
is solved first with finite difference gradients, then with analytic gradients.
.RUN
PRO Nlp_grad, x, iact, result
CASE iact OF
0:result = [ 2 * (x(0) - 2.), 2 * (x(1)-1.)]
1:result = [1., -2. ]
2:result = [-0.5*x(0), -2.0*x(1)]
ENDCASE
RETURN
END
.RUN
PRO Nlp_fcn, x, iact, result, ierr
tmp1 = x(0)-2.
tmp2 = x(1) - 1.
CASE iact OF
0:result = tmp1^2 + tmp2^2
1:result = x(0) -2.*x(1) + 1.
2:result = -(x(0)^2)/4. - x(1)^2 + 1.
ENDCASE
ierr = 0
END
; Ex #1, Finite difference gradients
ans1 = CONSTRAINED_NLP('nlp_fcn', 2, 2, MEQ = 1)PM, ans1, title='X with finite difference gradient'
; Ex #2, Analytic gradients
ans2 = CONSTRAINED_NLP('nlp_fcn', 2, 2, MEQ = 1, $ GRAD = 'nlp_grad')
PM, ans2, title='X with Analytic gradient'
; This results in the following output:
; X with finite difference gradient
; 0.822877
; 0.911439
; X with Analytic gradient
; 0.822877
; 0.911438
Version 2017.0
Copyright © 2017, Rogue Wave Software, Inc. All Rights Reserved.
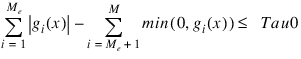
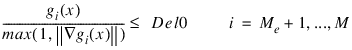
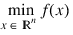
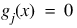 ,
, 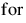
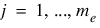
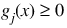 ,
,