The IP abstraction object
Perforce IPLM IPs abstract out managed design blocks. By organizing designs at the IP level a common interface is applied to many disparate sources of design data. IP states can be captured and published to the central Perforce IPLM server. Automation can be run based on events in the IP Lifecycle, and metadata can be gathered and applied automatically back on IPs and releases.
What is an IP?
IP contents
IPs are the core metadata abstraction object in Perforce IPLM. Each IP represents a component in a design. IP objects capture or link to metadata that describes a design component, but IPs don't store component design files directly. Instead IPs maintain a pointer into file level Data Management (DM) systems to the location of the component's files. IPs can access the file level contents of their component, and can capture the state of those files in a release, or IP Version (IPV). The contents of these releases, or IPVs, are stored on the Perforce IPLM Platform as versioned file lists, tags, changelists, revision numbers, or SHA numbers, depending on the appropriate method for a given DM system.
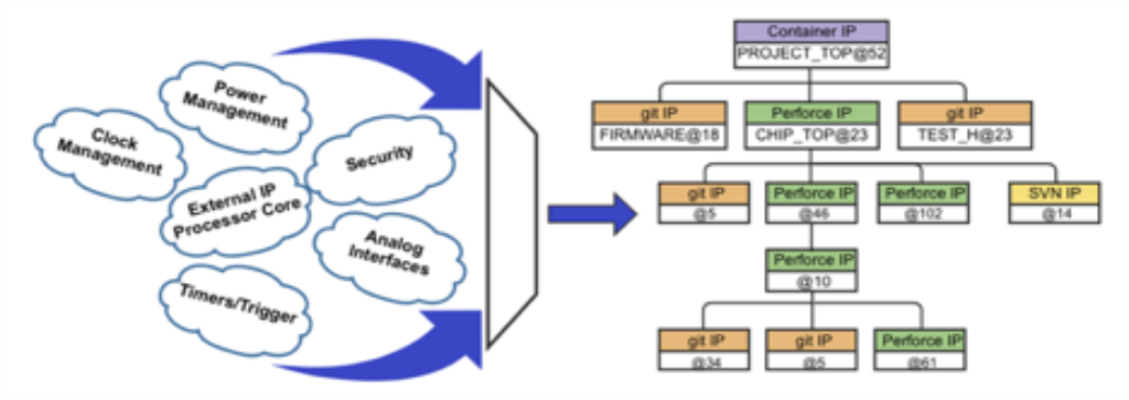
IP Hierarchy - Component and IP BOM (CIPB)
In addition to capturing the contents of an IP component in a release, the IPV also captures dependencies on other IP components at specific versions. In capturing dependencies on other IPVs, Perforce IPLM builds up a Component and IP BOM (CIPB), or IP Hierarchy. This hierarchy can be any number of levels deep. Each IPV in the IP Hierarchy is the same type of IP object as any other, so different levels of hierarchy can be used in their own context. A subsystem can be loaded into a workspace and developed, simulated and released. This same subsystem can be loaded in another workspace as a resource of a larger project or SOC where the subsystem becomes just one subset of the higher level IP Hierarchy.
By abstracting each component as an IP in Perforce IPLM, multiple disparate, siloed, systems can be unified into the common Perforce IPLM platform. A CIPB consisting of IPs that manage data in entirely different DM systems becomes trivial in Perforce IPLM. The correct release of a git based IP can be tracked along with its dependency on a particular release of a Perforce based IP, and the Perforce IP's dependency on several other IPs of whatever DM type can be tracked just as easily. Each is represented as an IP in Perforce IPLM, each has the same capabilities in the Perforce IPLM platform, they only differ in how their design files are managed.
Everything is an IP
IPs manage a set of files, with no restrictions on what the set of files is or contains. This means that anything important to the design can be managed as an IP.
- Traditional IPs: Internally developed or externally licensed IPs, i.e. PDKs, memories, communication components, processor cores, etc.
- Design IPs: Project components and subsystems, which might be eligible for reuse, or project specific
- IP Lines (Branches): Derivative or new components
- Engineering Environments and Configurations:
- Tools versions, including functional safety certifications
- Environment settings
- Project configuration and setup
- Automation scripts
Anything important to recreating the state of the design should be managed as an IP or attached to an IP. If the data is captured in a Perforce IPLM release, the design state can be recreated even many years later.
What does an IP do?
IPs have a wide range of capabilities and properties within the Perforce IPLM platform, beginning with the ability to capture the state of a design in a release. Releases are an exact record of the state of the design at the time they were created. Once captured, an IP release is foundational to the traceability provided by the Perforce IPLM platform.
Metadata capture
In addition to capturing the design state in releases, IPs can capture and centrally publish metadata about the IP component.
- Attributes and Widgets: Automatically capture and display graphical information on IPs and their releases. Used to build data sheets for display on IPs in the catalog.
- Properties: Typed, predefined values that extend the underlying IP data model. These are displayed on IPs and are easily searchable on the platform.
- Aliases: Indicators of IPV release quality levels that can be used to automatically integrate new qualified releases into the CIPB.
- External Systems: External data sources can be queried and their data displayed in the Perforce IPLM context
- Perforce IPLM API: Perforce IPLM's REST API can be used to access data from within Perforce IPLM in other systems or applications.
Workspace creation and management
IP releases can be used to create workspaces that exactly match the content and IP Hierarchy (CIPB) captured in the original release. This removes any uncertainty or effort that might otherwise be spent to confirm or validate a particular design configuration. When new releases are made, either of the top level IPV used to create the workspace, or of sub component hierarchies of that top level IPV, Perforce IPLM manages the integration of that new content through workspace updates. Similarly once new configurations are built in a workspace, that state can be captured in a new release and published back to the Perforce IPLM platform.
Centralized workspace management in Perforce IPLM has the following advantages:
- Configuration: Workspaces can be configured and standardized across teams, or the whole organization, using Project Properties set on the IP Hierarchy.
- Traceability: Workspaces that are built from IPs are tracked and queried from the central server, including current contents, owner, location and status
- IP Caching: Perforce IPLM Cache populates read only IP versions on disk. The cache accelerates workspace loads, and provides a staging area that ensures no local modifications for tapeouts.
- Update/Integration Management: Perforce IPLM Workspaces utilize a structured and systematic method for brining in new updates and creating new releases
- Snapshots: Full workspace state can be shared between users without a full release. Snapshots are useful for debugging, and providing hot fixes and patch updates.
- Workspace Permissions: unix group and ACL settings can be configured and deployed in the local workspace and PiCache
Automation
Perforce IPLM's centralized tracking is an ideal platform on which to trigger automation.
- Events: in the Perforce IPLM platform are published whenever any material action is performed on the database, these events can be used to continuous integration or other automated flows.
- Client Side Hooks: provide automation around client side events in Perforce IPLM, and include pre and post release, update and load hooks
- Server Side Hooks: Centralized control leveraging customer defined business logic can be applied to server side actions
Cataloging and publication
Centralization means everything that is captured in Perforce IPLM is available (given the correct permissions) to any consumer in the organization. IPs along with all the information to recreate their releases, and understand their status through metadata are centrally available from the command line or web catalogs and summary pages. Everything from project requirements and bug tracking down to the individual file versions captured by each Perforce IPLM release can be immediately viewed and understood.
IP DM types
DM IPs
DM IPs have a pointer into a Data Management (DM) system. Depending on the DM they are associated with they will capture their file release data differently, based on the DM implementation.
Container IPs
Container IPs are identical to DM type IPs, differing only in that they don't have a connection to managed data in a DM system. They are instead used to either contain resource IPs that could potentially be DM or container types, or they can be used as resources to other higher level parent IPs. Container IPs are useful for the organization and release of other sets of IPVs. They store metadata and interface into external systems exactly like other IPs.
File System IPs
File System IPs are often useful for managing large sets of data that may not make sense to add into a DM system directly, e.g. large PDKs or standard cell libraries. For these File System IPs, the DM is a location on a shared disk, with each release of a File System IP being a new location on disk that contains a new set of data representing that release.
Storing Filesystem IPs does require that the storage drive be accessible to all sites in the organization.
Capturing Design as a Release or IP Version
Perforce IPLM Releases capture the state of the design at the point when they are created. Two main things are captured in an IP Release:
-
File Level Contents of an IP: Files are managed in the DM system, Perforce IPLM captures the metadata to reconstruct the right files out of the DM system that make up the release.
Because Perforce IPLM is only working with metadata to describe the release rather than the DM files themselves, Perforce IPLM releases can be extremely lightweight when compared to DM level tagging or labeling operations which are often done on a file by file basis. - IP Resources: Each IP has a resources field which allows it to specify the other IPs in the system that are its dependencies. Each IP can be a parent of some IPs, and a child of yet other IPs through the relationships specified in the resources field of each IP, thereby building up an IP Hierarchy.
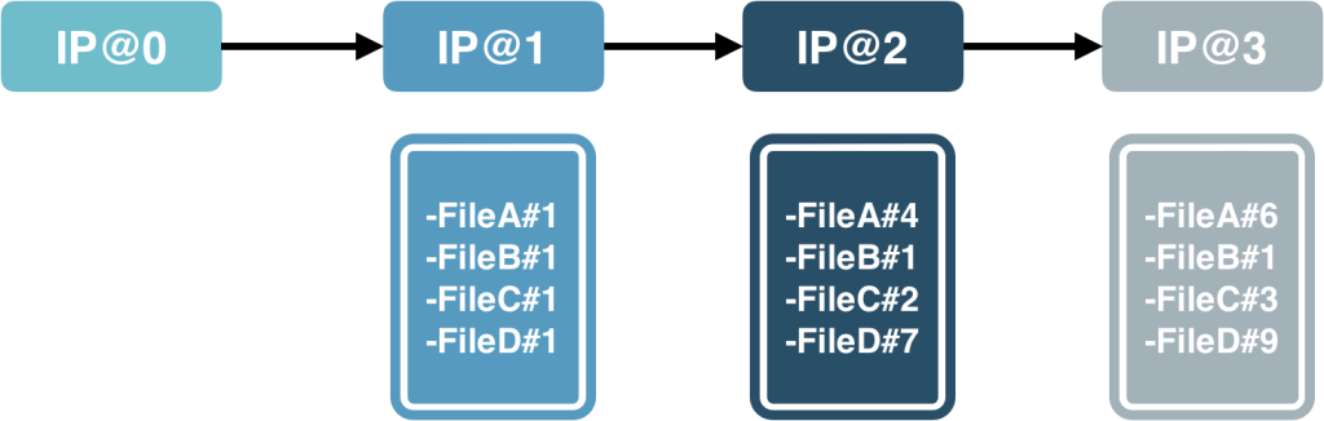
File Contents in DM IP Releases
Perforce format IP contents are pictured in this diagram. Each release of the IP captures a set of files that make up the contents of the release. When the IP is populated into the workspace the IPs captured file list will be populated into the workspace at the specified versions in the release.
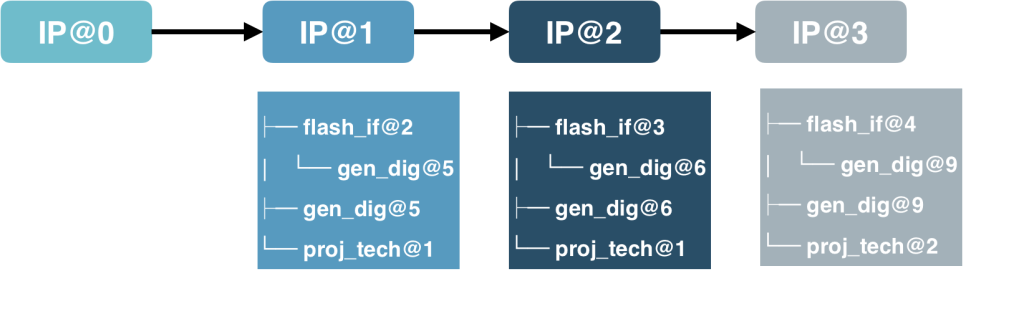
IP Resources in IP Releases
Any IP type can have IP resources, when the IP is released the versions of its resources are captured as part of the release. IPV resources are specified in the IPV's resources field. In addition to the files captured as part of the IPV's contents, each IPV can have defined resources which are IPVs at the particular releases needed for the parent IPV's release. Each of these IPV resources can have its own set of file contents, all at the correct versions corresponding to that IPV's release. These resources can also have their own set of resources, and those resources will have their own set of files. In this way a large, exact set of data can be built up and referred to concisely with the top IPV name, as all resource IPVs and associated file level data is specified by just the top level IPV release name.
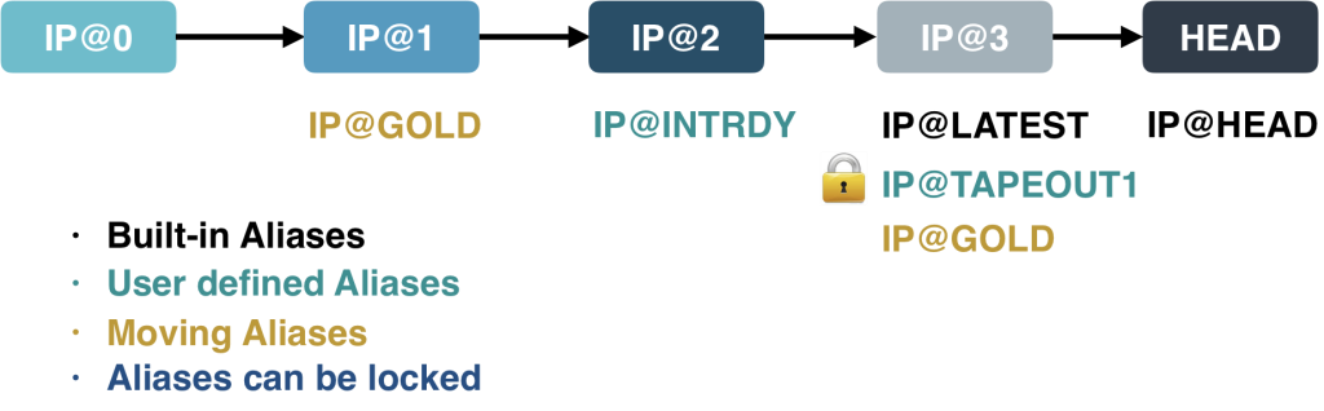
Aliases
Instead of referring to an IPV by its numerical release, meaningful names can be applied to each release or to multiple releases if desired. These Alias names can be defined as needed for a given flow. Aliases are normally used when specifying quality level, or indicating which releases have special importance, e.g. which was the tapeout version, etc.
Moving Aliases
Adding the same alias to multiple IPVs on a given IP creates a Moving Alias. If an IPV is specified as using a Moving Alias, the IPV that has the latest underlying release version with that Alias applied will be returned when that alias is requested. If the GOLD alias is on IP@1 only, requests for IP@GOLD will return IP@1. Once the 'GOLD' alias is applied to IP@3, subsequent calls for IP@GOLD will return IP@3 instead. If the alias GOLD is removed from IP@3, then IP@1 will again be returned.
Locking Aliases
If a particular alias will no longer be applied to the releases on a particular IP Line, the alias can be locked. This prevents further applications or removals of the Alias from that line unless certain conditions are met. This can be used to apply an ALIAS to a single IPV on a line (@TAPEOUT1) or to prevent additional applications of an Alias after a certain release.
Special built in Aliases
@LATEST
The @LATEST alias is automatically applied to the latest release of an IP Line by Perforce IPLM, as soon as a new release is made. This allows updating to IP@LATEST and always getting the most recent Perforce IPLM release. If IP@10 is the latest release on the line, IP@LATEST will return the IP@10 release, with its file contents and resource tree.
@HEAD
The @HEAD alias is similar to @LATEST, as it returns the IP resources associated with the latest release in Perforce IPLM. However instead of the file contents of the latest Perforce IPLM release it returns the latest files checked into the DM system, whether they are part of a release or not. Users that are working on the design of a particular IP may want to use the @HEAD alias to bring in the latest DM files and the latest IP release. A similar result is achieved by running pulling in a fixed release and then updating the files in the DM system, so this is a consideration before using @HEAD.
Aliases and hierarchy
IPVs in the IP Hierarchy can be included via an alias rather than the fixed release version. This has the advantage of bringing in updated IP@ALIAS versions into a workspace automatically as soon as they are available, but means that a release that includes aliases is not entirely fixed as it would be if the hierarchy referenced only fixed releases. IPs at aliases might be included in hierarchies in the earlier and middle portions of a project, but by later on in a project IPV references should be converted over to fixed release based hierarchies.
Unique Aliases
A Unique Alias applies to only a single IPV across all of the lines of an IP at a single time. Unique Aliases are different from locked aliases in that it is possible to use a non-unique alias on some number of the lines of a given IP, and to lock it to a version on each line while Unique Aliases can only be used once per IP. These Unique Aliases are often useful in flows that leverage a number of lines on a single IP, as they allow specification of a single IPV across all relevant lines without having to know which line the desired IPV is on.