Parallel checkpointing, dumping, and recovery
The p suboption to -jc, -jd and -jr allows the use of parallel threads for writing to, and reading from, multiple checkpoint files, one per database table.
For example, to specify four parallel threads for creating a checkpoint, use 4 for the -N numberOfThreads option:
p4d -r . -N 4 -jcp cp
outputs:
Checkpointing files to cp.ckp.9154...
Similarly, to specify four parallel threads for restoring metadata, use 4 for the -N numberOfThreads option:
p4d -r . -N 4 -jrp cp.ckp.9154
outputs:
Recovering from cp.ckp.9154...
Although the number of parallel threads is typically controlled by the db.checkpoint.threads configurable, the two examples above with -N numberOfThreads show that the command line can override that value.
The -jcp and -jdp options take a directory name as a parameter. The directory name is used as a prefix for the full directory name of the checkpoint. For example, passing cp creates a directory named cp.ckp.9154. The path is relative to P4ROOT unless you specify an absolute path, starting with / or \, or a drive letter such as C:.
The -jrp option requires the full directory name, such as cp.ckp.9154.
The m multi-file option is available for:
-
Parallel Checkpoint and journal options. For example,
-jcpm [-N numberOfThreads] [-Z | -z] [prefix] -
Parallel Journal dump and restore filtering. For example,
-jdpm [-N numberOfThreads] [-Z | -z] [prefix]
where
-
If
[-N numberOfThreads]is omitted, thedb.checkpoint.threadsconfigurable determines the number of threads to use for the checkpoint. -
-Zcompresses the checkpoint,-zcompresses both the checkpoint and journal, and if neither-Znor-zis included, no compression occurs. To learn more, see P4 Server (p4d) reference.
File naming convention within a recovery directory if using parallel option
After a successful checkpoint or dump operation, P4 Server creates a checkpoint file for each database table in this directory. For example, the table db.xxx is written to a file named db.xxx.ckp (or db.xxx.ckp.gz if compressed).
For example, checkpointing two tables produces the following files:
db.archive.ckp.gz
db.archive.ckp.gz.md5
db.archmap.ckp.gz
db.archmap.ckp.gz.md5
...or, for a non-compressed checkpoint or dump:
db.archive.ckp
db.archive.ckp.md5
db.archmap.ckp
db.archmap.ckp.md5
...The files with the .md5 suffix contain the MD5 sum of their matching replay file.
When the multi-file suboption (m) is specified, the files for a specific table db.xxx are named db.xxx#bbbbbbbb.ckp, where each file name has a distinguishing batch number (b) after the # separator. The batch number consists of eight (8) lowercase hexadecimal digits. For example:
...
db.config.ckp.gz
db.config.ckp.gz.md5
...
db.revcx#00000001.ckp.gz
db.revcx#00000001.ckp.gz.md5
db.revcx#00000002.ckp.gz
db.revcx#00000002.ckp.gz.md5
db.revcx#00000003.ckp.gz
db.revcx#00000003.ckp.gz.md5
db.revcx#00000004.ckp.gz
db.revcx#00000004.ckp.gz.md5
db.revcx#00000005.ckp.gz
db.revcx#00000005.ckp.gz.md5
db.revcx#00000006.ckp.gz
db.revcx#00000006.ckp.gz.md5
db.revcx#00000007.ckp.gz
db.revcx#00000007.ckp.gz.md5
db.revcx#00000008.ckp.gz
db.revcx#00000008.ckp.gz.md5
db.revcx#00000009.ckp.gz
db.revcx#00000009.ckp.gz.md5
db.revcx#0000000a.ckp.gz
db.revcx#0000000a.ckp.gz.md5
...
db.locks#00000001.ckp.gz
db.locks#00000001.ckp.gz.md5
db.locks#00000002.ckp.gz
db.locks#00000002.ckp.gz.md5
db.locks#00000003.ckp.gz
db.locks#00000003.ckp.gz.md5
...Example: Restoring from a multi-file parallel checkpoint
To create a parallel, multi-file checkpoint (with compression), run:
p4d -r /p4/1 -jcpm -N 8 -Z cp
This produces a recovery directory (for example, cp.ckp.9154/) beneath P4ROOT containing one or more files per table. If the prefix (cp) is provided without a path, the recovery directory is created inside P4ROOT.
When m (multi-file) is used, large tables are split into batches and files are named as follows:
db.<table>#<bbbbbbbb>.ckp[.gz]
where <bbbbbbbb> is an 8‑digit lowercase hex batch id.
Each .ckp (or .ckp.gz) has a matching .md5 file, for example:
/p4/1/cp.ckp.9154/
├── db.user.ckp.gz
├── db.user.ckp.gz.md5
├── db.protect.ckp.gz
├── db.protect.ckp.gz.md5
├── db.revcx#00000001.ckp.gz
├── db.revcx#00000001.ckp.gz.md5
├── db.revcx#00000002.ckp.gz
├── db.revcx#00000002.ckp.gz.md5
├── db.locks#00000001.ckp.gz
├── db.locks#00000001.ckp.gz.md5
└── ...
To restore metadata from this checkpoint, run the following during a quiet period:
p4d -r /p4/1 -N 8 -jrp cp.ckp.9154
This command:
-
Restores in parallel using 8 threads (
-N 8). -
Reads the multi-file checkpoint set from the recovery directory
cp.ckp.9154. If you specify a relative path, it is relative toP4ROOT.
Related commands:
-
Create parallel/multi-file checkpoint:
p4d -r /p4/1 -jcpm -N 8 cp -
Restore in parallel from directory:
p4d -r /p4/1 -N 8 -jrp cp.ckp.9154
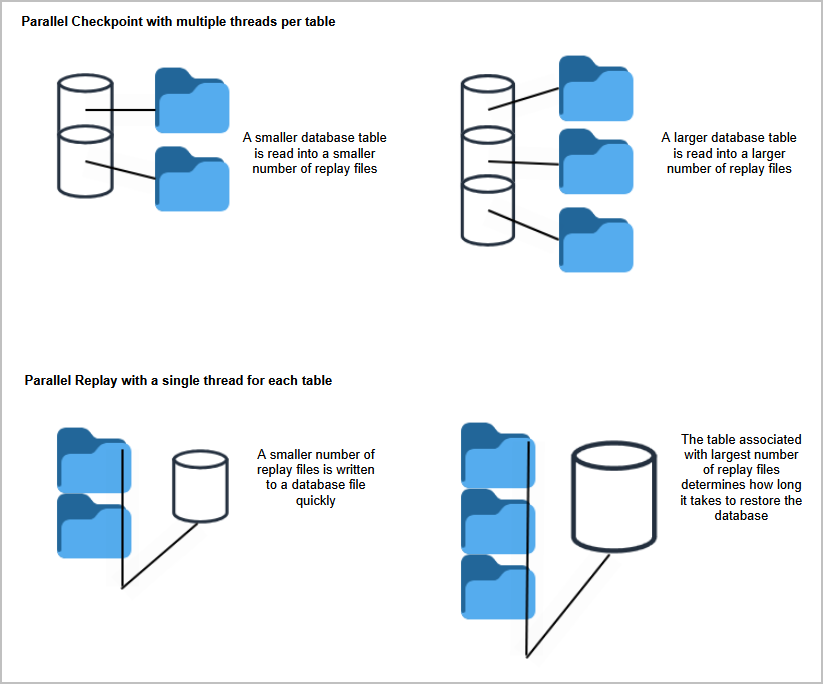
The m suboption might improve performance
When the p suboption is specified for a dump or checkpoint operation, each table is dumped into its own file in the checkpoint directory. At some sites, a few of the tables, such as db.have and db.integed, might be so large that the checkpoint operation needs more time for them than for tables of an average size. The m suboption causes any large table to be split into multiple output files in the checkpoint directory. With multi-threading, these output files are processed in parallel for the checkpoint operation.
Parallel checkpoint might be faster than parallel restore
A parallel checkpoint can be faster than parallel restore. For example, a parallel checkpoint with the m suboption, such as
p4d -r . -N 8 -jcmp
can be faster than omitting the m suboption,
p4d -r . -N 8 -jcp
because multiple threads read in parallel from multiple tables.
However, the subsequent parallel restore,
p4d -r . -N 8 -jrpdedicates a single thread to each table. Each of these single threads ensures database integrity by writing to each database file in the correct key sequence. Therefore, the time required for restoring the metadata is determined by the size of the largest table to be restored.
How to know the parallel checkpoint has completed
You can determine when a checkpoint has completed with either of these two methods:
-
(Recommended) Poll the checkpoint history (
ckphist) record because this method works whether the checkpoint failed or succeeded. This method was introduced in P4 Server version 2023.1.1 -
Poll for the existence of the
md5file, which does not indicate when a checkpoint has failed.
Poll for the ckphist record
The syntax to poll the ckphist record is
p4d -xj --jnum ckpnumwhere ckpnum is the checkpoint number used to name the checkpoint file and directory.
The checkpoint command reports:
$ p4d -jcmp
Checkpointing files to checkpoint.4...Example shell script:
#!/usr/bin/bash
P4D=$HOME/bin/p4d
# Start the multi-file checkpoint request
$P4D -r . -jcmp -N 4 > out &
sleep 1
# Read the output from p4d
out=`cat out`
# Extract the checkpoint number from the p4d output
ckpnum=`expr "$out" : '.*checkpoint\.\([0-9]*\).*'`
# Search for the ckphist record for that checkpoint number
rec=`$P4D -r . -xj --jfield="startDate,endDate,jfile,failed" --jnum "$ckpnum"`
# See what we've got
echo "Found " $recPoll for the md5 file
In the same directory that contains the checkpoint or dump directory, look for the consolidated .md5 file. This file is created when the operation has completed, whether the operation was successful or not. In the following example, line 6 shows that checkpoint.3.md5 in the name of this file.
$ p4d -r . -jcmp -z
Checkpointing files to checkpoint.3...
Rotating journal to journal.2.gz...
$ ls checkpoint.*
drwxrwxr-x 2 perforce perforce 12288 Jun 29 11:11 checkpoint.3
-r--r--r-- 1 perforce perforce 9784 Jun 29 11:11 checkpoint.3.md5
$ The checkpoint.3.md5 file consists of one line for each checkpoint file created in the checkpoint directory, with each line including the checkpoint file name, MD5 digest, and the epoch time stamp. For example:
MD5 (checkpoint.3/db.config.ckp.gz) = 5A32E66EE638A52F480F476B0B78191E 1688033506
MD5 (checkpoint.3/db.configh.ckp.gz) = B26E2EBA2E35B5F138792549A585276D 1688033506
MD5 (checkpoint.3/db.counters.ckp.gz) = D9A5E3CE0728B6206E4A746CB6854994 1688033506
MD5 (checkpoint.3/db.nameval_00000001.ckp.gz) = 035080F2CDFDB5BE9FC5E9D640CF5ABA 1688033506
MD5 (checkpoint.3/db.nameval_00000004.ckp.gz) = 7D052BA5C906C7C3087FE49DB4FCD48D 1688033506
...The ordering of the records is significant. Checkpoint files that were completed first by a parallel thread are at the top of the file.
Prefix for parallel checkpoints
Checkpoint files are placed into a newly-created directory based on the prefix for the checkpoint or dump. Specifying a prefix on the p4d -jcp command overrides the prefix set by the journalPrefix configurable.
Configurables for tuning checkpoints
The values and purpose of the configurables that you can use to tune checkpoints:
|
Configurable |
Default |
Min |
Max |
Use |
|---|---|---|---|---|
db.checkpoint.reqlevel
|
4
|
2
|
20
|
Only database files at this level or deeper in the btree are considered to be split into multiple checkpoint files during a checkpoint or dump request. |
db.checkpoint.worklevel
|
3
|
2
|
20
|
The page level examined within a database table that supplies the record keys used to split that table during a multi-file checkpoint operation. |
db.checkpoint.numfiles
|
10
|
1
|
20000
|
Used to determine how many checkpoint files should be generated during a multi-file checkpoint operation. This value can be overridden by the --numfiles option of p4 dbstat command. |
db.checkpoint.threads
|
0
|
0
|
4096
|
Maximum number of threads to use in a checkpoint, dump, or recovery. The value must be 2 or greater for a multi-file request to split a table. Many factors such as CPU, memory, disks, controllers, file system, and system load might affect performance. Start with a value such as 4, 6, or 8, then monitor processor and I/O performance to determine whether a larger value is appropriate for your system. |
How the number of checkpoint files is calculated
The value of numfiles is used to determine the number of keys to generate. The total number of pages found at the worklevel is divided by the "effective numfile" (en) value. The effective numfile value is calculated by this formula:
en = n (a - w)
where
n is the value of db.checkpoint.numfiles
a is the depth of the current database file, and
w is the value of db.checkpoint.worklevel
For example, if a = 5, w = 3, and n = 10,
then 10 ^ ( 5 - 3), which is 10 ^ 2 = 100
so in this case setting db.checkpoint.numfiles to 10 results in 100 effective numfiles.